Convolutional Neural Networks: Introduction
Take a moment to observe and look around you. Even if you're sitting still on your chair or lying on your bed, your brain is consistently attempting to analyze the dynamic world around you. Without your conscious effort, your brain is incessantly creating predictions and acting upon them.

After just a brief look at this picture, you identified a restaurant at the beach. You immediately recognized some of the objects within the scene as plates, tables, lights, etc. You most likely conjointly guessed that weather is excellent to take a night walk. However, were you able to make those predictions? However, did you establish the many objects within the picture?
It took nature lots of years of evolution to attain this outstanding achievement. Our eyes and our brain work in excellent harmony to create such stunning visual experiences. The system that makes this potential for us is the eye, visual pathway, and cortical area within our brain.
A system inside us allows us to make sense of the picture above, the text in this article, and all other visual recognition tasks we perform daily.
We've been doing this since our childhood. We learned to recognize a dog, a cat, or a human being. Can we teach computers to do so? Can we make a machine that can see and understand as well as humans do?
The answer is yes! Similarly, how a child learns to recognize objects, we need to show an algorithm millions of pictures before generalizing the input and making predictions for images it has never seen before.
The computers "see" the world in a very completely different manner than we tend to do. They can only "see" something in kind of numbers, something like this:

To teach computers to make sense out of this array of numbers is a challenging task. Computer scientists have spent decades building systems, algorithms, and models that can understand images. Today in the era of Artificial Intelligence and Machine Learning, we have achieved remarkable success in identifying objects in images, identifying the context of an image, detecting emotions, etc. Convolutional Neural Networks or CNNs are among the most popular computer vision algorithms these days.
Convolutional Neural Networks:
Convolutional Neural Networks have a distinct design from regular Neural Networks. Traditional Neural Networks usually transform an input by sending it through a series of hidden neural network layers. Each layer is created of a collection of neurons, where every layer is fully connected to all neurons within the layer before. Finally, an "output layer" is the last fully connected layer representing the predictions.
Convolutional Neural Networks are a bit different. First of all, each layer is organized into three dimensions: width, height, and depth. Further, the neurons in one layer do not connect to all the neurons within the subsequent layer solely to a tiny region. Lastly, the final output will be reduced to one vector of likelihood scores, organized along the depth dimension.
CNN is composed of two major parts:
- Feature Extraction: In this part, the Neural Network performs a series of convolution operations and pooling operations throughout which the features are detected. If you would have a zebra picture, this is the part where the network would acknowledge its stripes, two ears, and four legs;
- Classification: Here, the fully connected layers function as a classifier on top of these extracted features. They will assign a likelihood for the object on the image to be what the algorithm predicts.
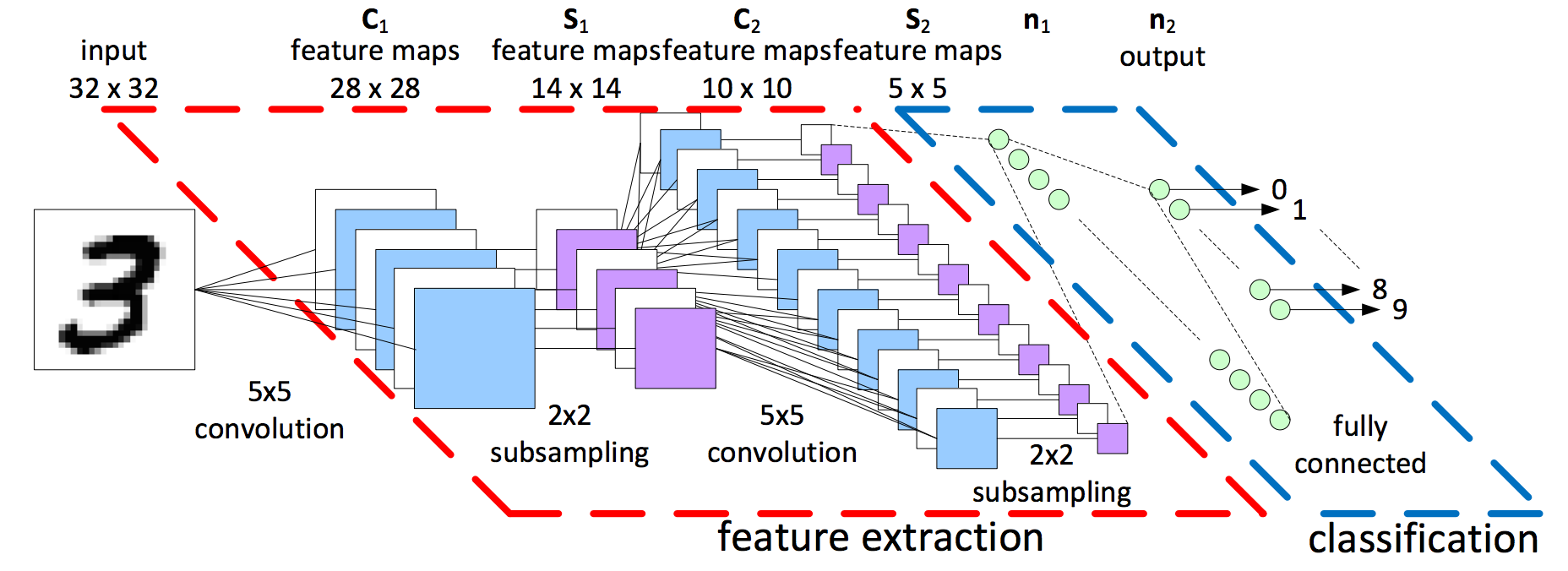
There are squares and lines inside the red dotted region, which we will break down later. The green circles inside the blue dotted region on the right side of the image are named classification. This neural network or multi-layer perceptron area acts as a classifier. The inputs to this layer (feature extraction) came from the preceding part called feature extraction.
Feature extraction is the part of CNN design from wherever this network derives its name. Convolution is the mathematical operation that is central to the effectiveness of this algorithmic program. Let's perceive on a high level what happens within the red self-enclosed region. The input to the red area is the image that we would like to classify, and therefore the output may be a set of features. Think about features as an example of the image; as an example, a picture of a cat may need features like whiskers, two ears, four legs, etc. A handwritten digit image may need features like horizontal and vertical lines or loops and curves. Later I will demonstrate to you how to extract such elements from the image.
Feature Extraction: Convolution
The convolution layer in CNN is performed on an associate degree input image using a filter or a kernel. To understand filtering and convolution, you'll need to scan the screen ranging from left to right and move down one step after covering the screen's width and repeating the same process until you're checking the entire screen.
For instance, if the input image and also if the filter seems like the following:
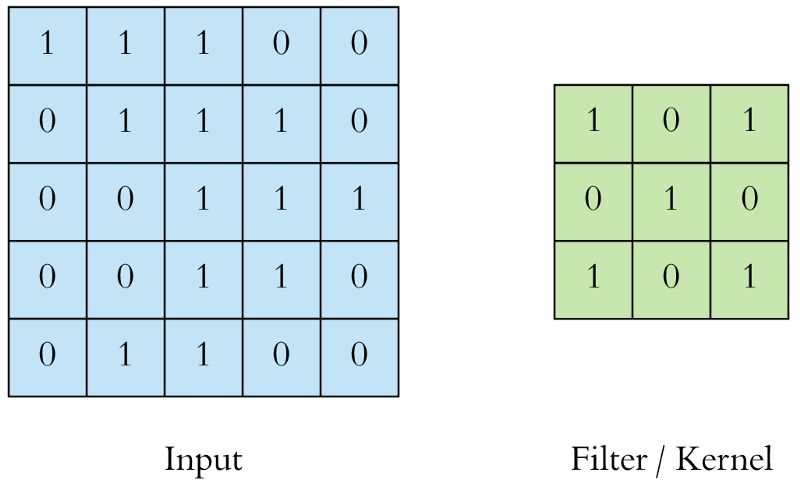
The filter (green) slides over the input image (blue) one step (pixel) at a time ranging from the highest left. The above-written filter multiplies its values with the overlapping values of the image whereas sliding over it and adding all of them up to output one value for every overlap till the whole image is traversed:
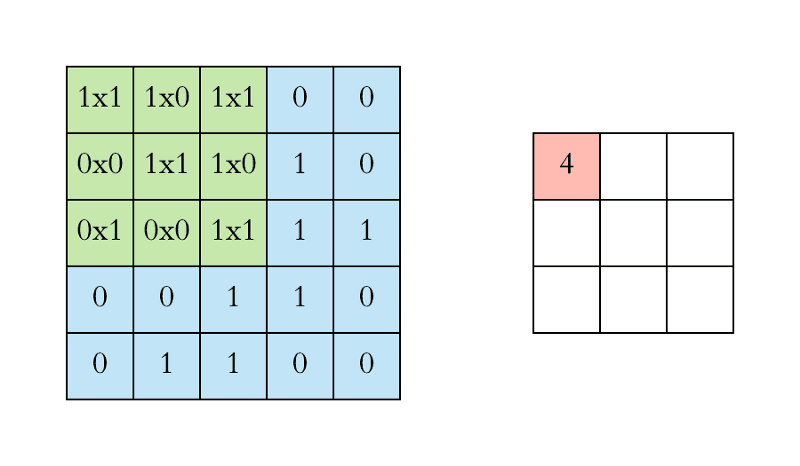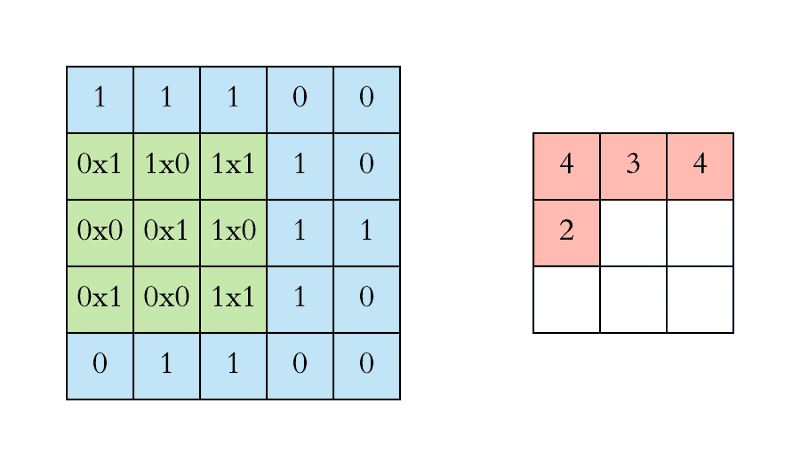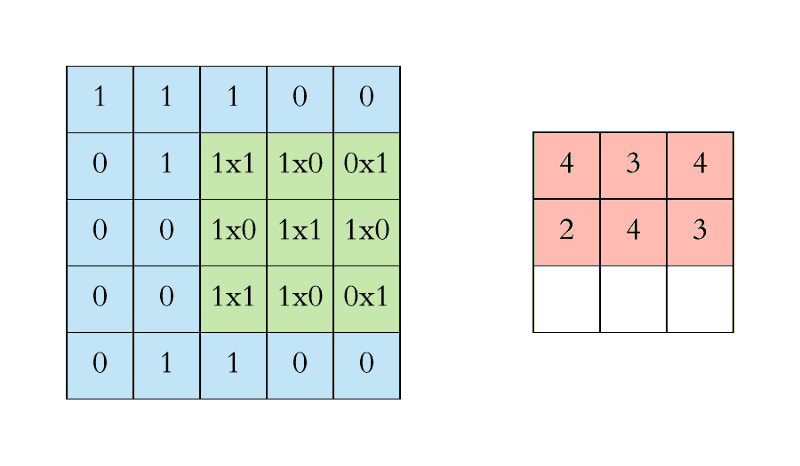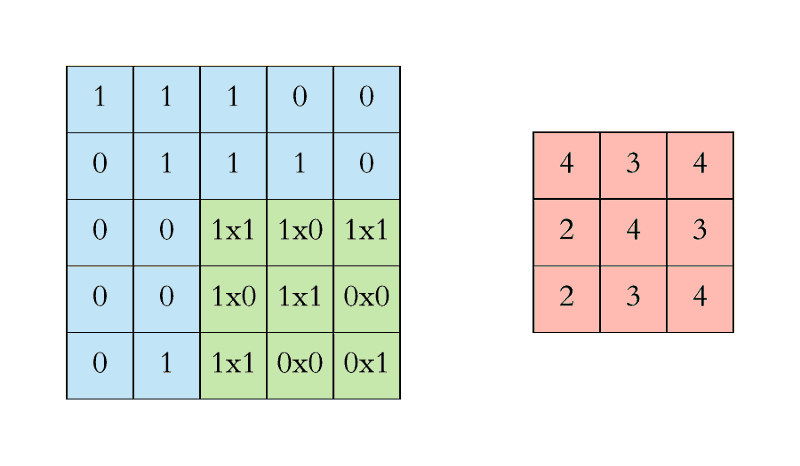
In the above gif animation, the value 4 (top left) in the red (right) output matrix corresponds to the filter overlap on the top left of the image, which we compute the following:
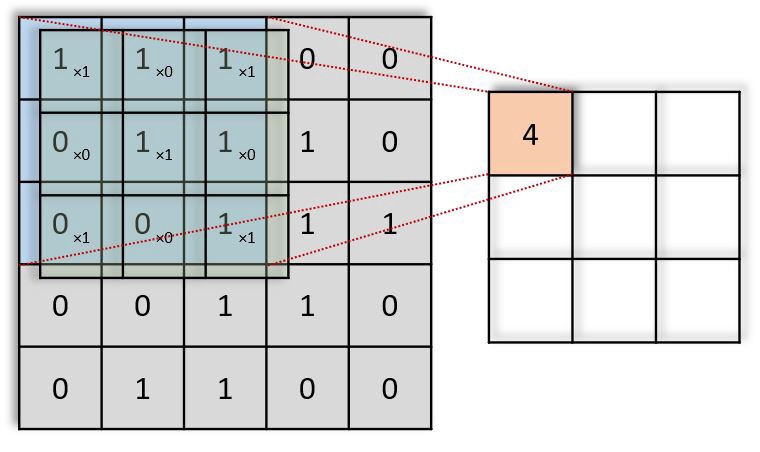
(1×1+0×1+1×1)+(0×0+1×1+1×0)+(1×0+0×0+1×1)=4
Similarly, we tend to compute the opposite values of the output matrix. Note that the top-left value, which is 4, within the output matrix depends solely on the nine values (3x3) on the top left of the original image matrix. It doesn't change even if the rest of the values in the image change. This is the receptive field of this output value or neuron within our CNN. Every value in our output matrix is sensitive to a specific region in our original image.
In images with multiple channels (e.g., RGB), the Kernel has the constant depth of the input image. Matrix operation perform between 𝐾𝑛 and 𝐼𝑛 stack ([𝐾1,𝐼1],[𝐾2,𝐼2],[𝐾3,𝐼3]) and all the results are summed with the bias to provide us a squashed one-depth channel Convoluted Feature Output:
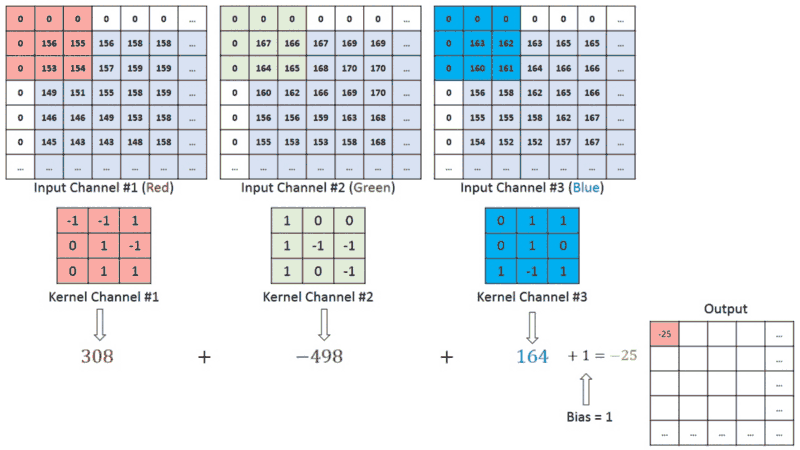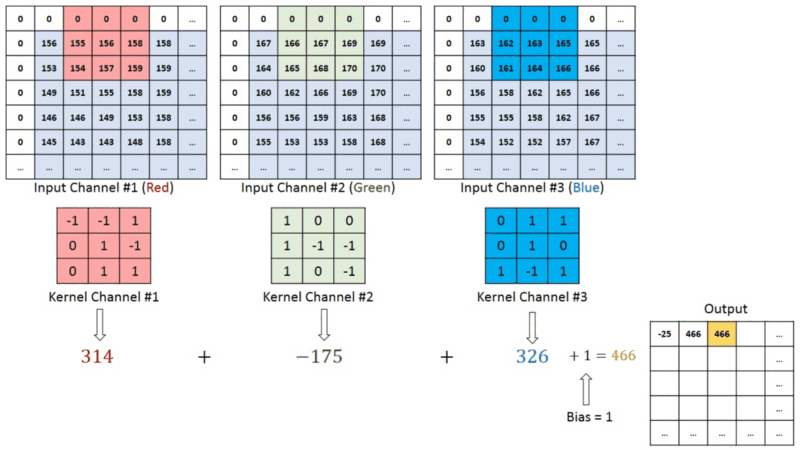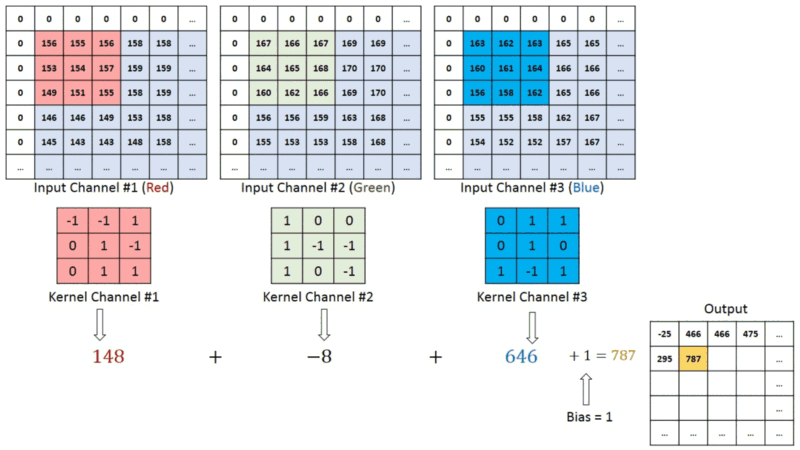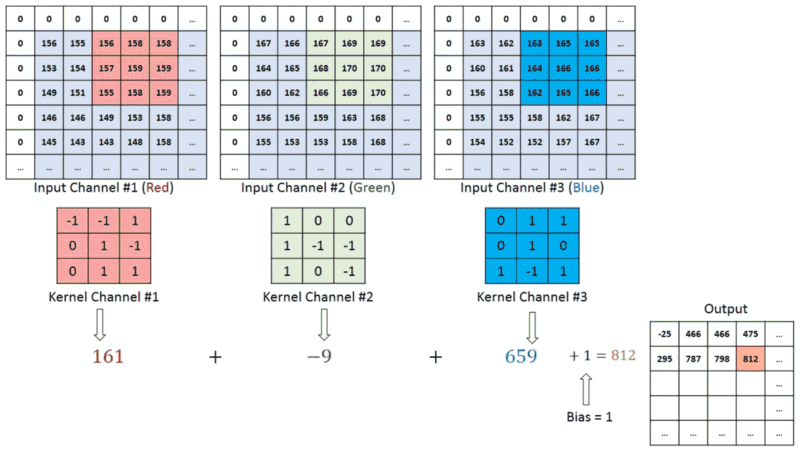
Each neuron within the output matrix has overlapping receptive fields. The animation below can provide you with a much better sense of what happens in convolution. Conventionally, the primary ConvLayer is responsible for capturing the Low-Level features like edges, color, gradient orientation, etc. With further layers, the architecture adapts to the High-Level features. It gives us a network encompassing a wholesome understanding of images within the data-set, the same as we might.
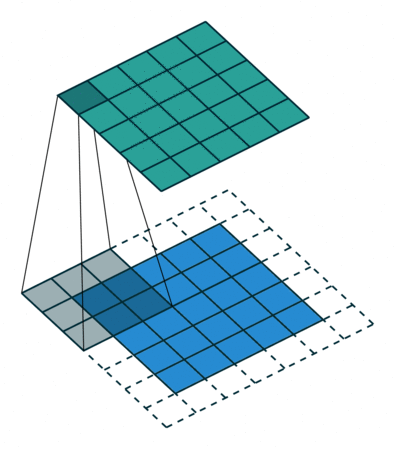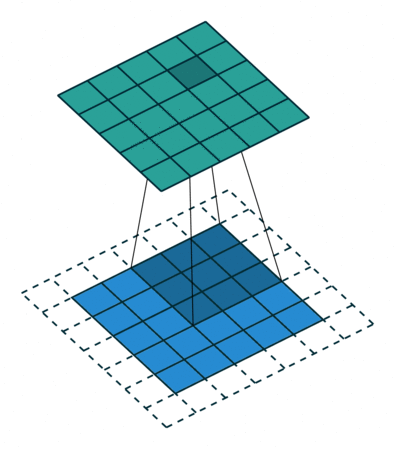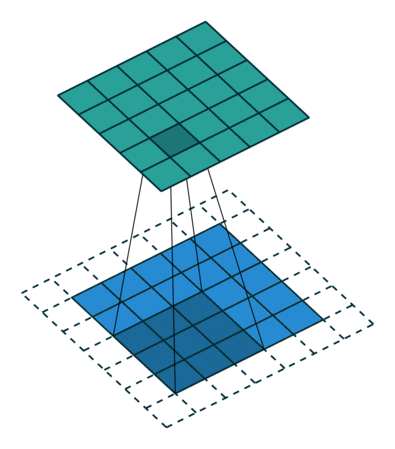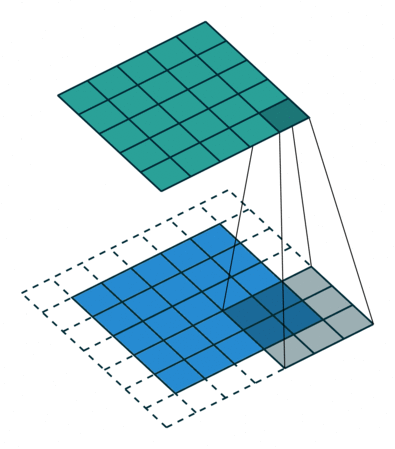
Feature Extraction: padding
There are two types of results to the operation. The first one is when the convoluted features are reduced in dimensionality compared to the input. The second is when the dimensionality is either increased or remains the same. This is done by applying Valid Padding or the Same Padding in the case of the latter. In the above example, our padding is 1.
In our example, when we augment the 5x5x1 image into a 7x7x1 image and then apply the 3x3x1 Kernel over it, we find that the convolution matrix turns out to be of dimensions 5x5x1. It means our output image is with the exact dimensions as our output image (Same Padding).
On the other hand, if we perform the same operation without padding, we'll receive an image with reduced dimensions in the output. So our (5x5x1) image will become (3x3x1).
Feature Extraction: example
Let's say we have a written digit image just like the one below. We want to extract out only the horizontal edges or lines from the image. We are going to use a filter or Kernel that, once convoluted with the initial image, dims out all those areas that don't have horizontal edges:

Notice how the output image only has the horizontal white line, and the rest of the image is dimmed. The Kernel here is like a peephole which is a horizontal slit. Similarly, for a vertical edge extractor, the filter is like a vertical slit peephole, and the output would look like this:

Feature Extraction: Non-Linearity
After sliding our filter over the original image, the output passes through another mathematical function called an activation function. The activation function usually used in most cases in CNN feature extraction is ReLu which stands for Rectified Linear Unit. That merely converts all of the negative values to zero and keeps the positive values the same:
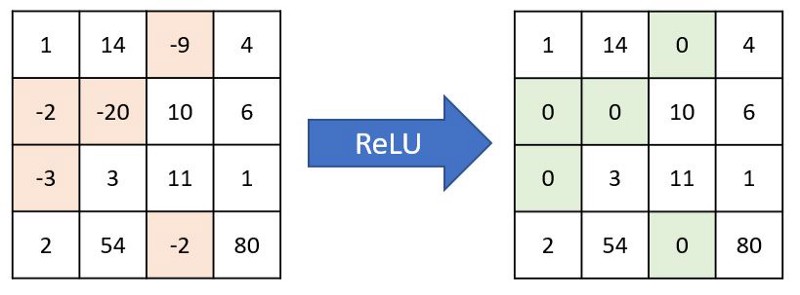
After passing the outputs through ReLu functions, they look like this:

So for a single image, we can get multiple output images by convolving it with various filters. We applied a horizontal edge extractor and a vertical edge extractor for the handwritten digit and got two output images. We can use several other filters to generate more such outputs images, also referred to as feature maps.
Feature Extraction: Pooling
After a convolution layer processing, once we get the feature maps, it's common to add a pooling or a sub-sampling layer in CNN layers. Like the Convolutional Layer, the Pooling layer is responsible for reducing the Convolved Feature's abstraction size, which often decreases the computational power needed to process the data through spatiality reduction. Pooling shortens the training time and controls over-fitting. Moreover, it helps extract dominant features rotational and positional invariant, thus effectively training the model.
There are two types of Pooling:
- Max Pooling process returns the maximum value from the portion of the image covered by the Kernel. Max Pooling additionally performs as a Noise appetite suppressant. It discards that noisy activation altogether and additionally serves de-noising along with dimensionality reduction.
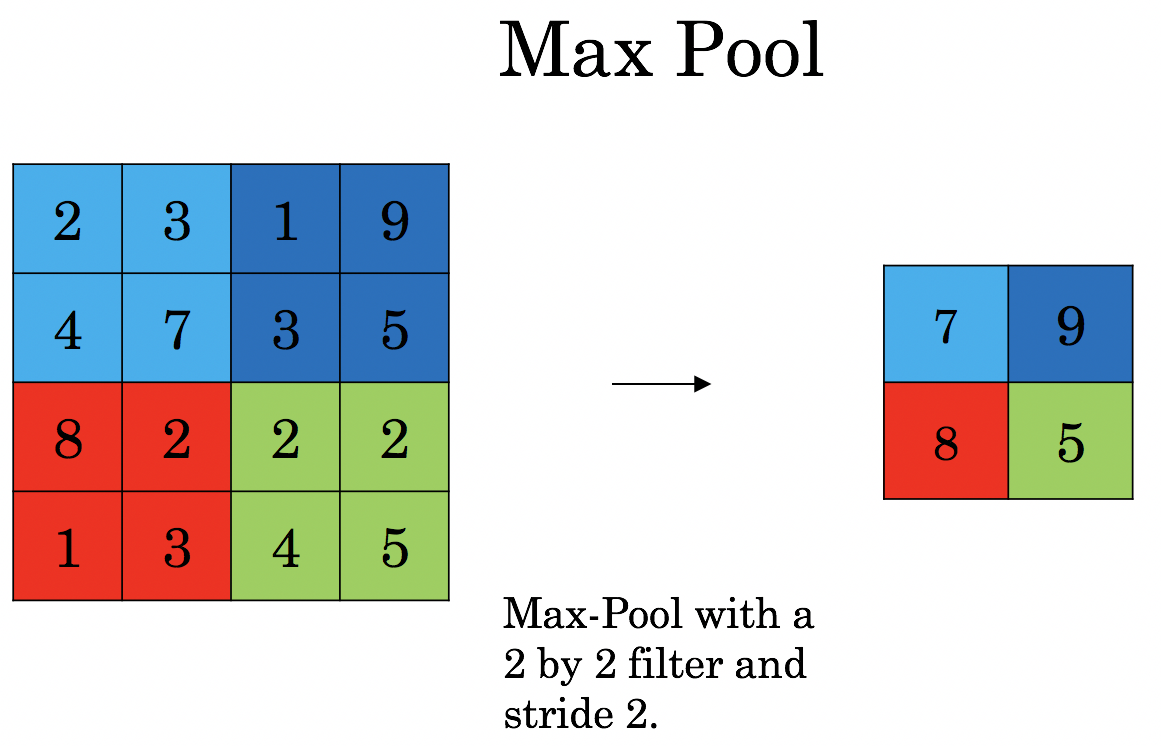
Max Pooling example - The average Pooling process returns the average of all the values from the portion of the image covered by the Kernel. Average Pooling merely performs spatiality reduction as a noise suppressing mechanism. Hence, we can say that Max Pooling performs a lot better than Average Pooling.

Average Pooling example
The Convolutional Layer and the Pooling Layer form the i-th layer of a Convolutional Neural Network. Depending on the complexities within the images, the number of such layers is also exaggerated for capturing low-levels details even further, however at the cost of additional computational power.
After going through the above method, we've got success and enabled the model to understand the features. Moreover, we will flatten the final output layer and feed it to a regular Neural Network for classification purposes.
Classification — Fully Connected Layer (FC Layer):
Adding a Fully-Connected layer may be a (usually) low-cost approach of learning non-linear combinations of the high-level features by the output of the convolutional layer, as shown below. The Fully-Connected layer understands a presumably non-linear function in that space. Example of CNN network:
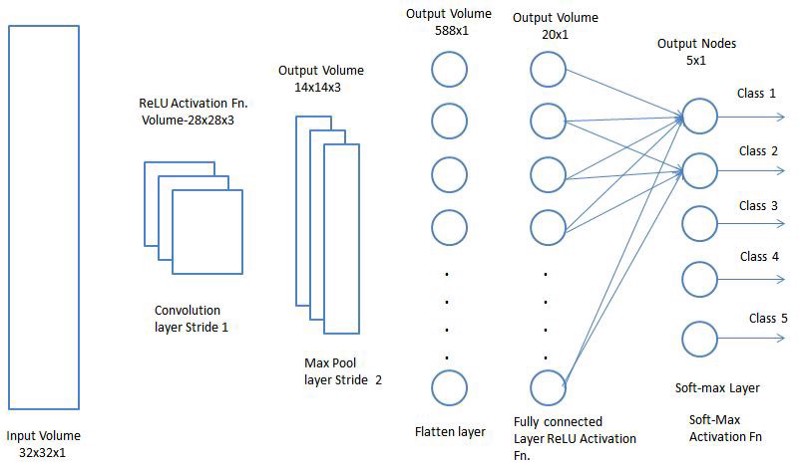
Now that we've converted our input image into an acceptable kind, we tend to flatten the image into a column vector. We feed the flattened output to a feed-forward Neural Network, and we apply backpropagation to each training iteration. After a series of epochs, the model can differentiate between dominating and certain low-level features in images and classify them exploitation the Softmax Classification technique.
So currently, we've all the pieces needed to make a CNN. Convolution, ReLU, and Pooling. We feed the output of max-pooling into the classifier we mentioned initially, which is usually a multi-layer perceptron layer. Typically in CNN's these layers are used more than once i.e. Convolution -> ReLU -> Max-Pool -> Convolution -> ReLU -> Max-Pool and so on. We won't discuss the fully connected layer in this article.
Conclusion:
CNN is a very powerful algorithm that is widely used for image classification and object detection. The hierarchical structure and powerful feature extraction capabilities from an image make CNN robust for various image and object recognition tasks.
Various architectures of Convolution Neural Networks are key in building algorithms that power and shall power AI within the predictable future. Some of them are ZFNet, AlexNet, VGGNet, LeNet, GoogLeNet, ResNet and etc.
Thanks for Reading! In my coming tutorial, we'll start building my first CNN model with TensorFlow.