
Welcome to part 5 of the TensorFlow Object Detection API tutorial series. First, you can download the code on my GitHub page. Then, in this part and a few in the future, we will cover how we can track and detect our own custom objects with this API.
I am doing this by using the pre-built model to add custom detection objects to it. That’s a decent jump from my findings, and it’s quite hard to locate any full step-by-step tutorials, so hopefully, I can help you with that. Once you finish this tutorial, you will have the ability to train for any custom object you can think of (and create data for) - that’s an awesome skill to have, in my opinion.
Alright, so this is my overview of the steps needed to do in this tutorial:
- Collect at least 500 images that contain your object - The bare minimum would be about 100, ideally more like 1000 or more, but the more images you have, the more tedious step 2 will be;
- Split this data into train/test samples. Training data should be around 80% and testing around 20%;
- Generate TF Records from these splits;
- Setup a .config file for the model of choice (you could train your own from scratch, but we'll be using transfer learning);
- Train our model;
- Export inference graph from the newly trained model;
- Detect custom objects in real-time.
TensorFlow needs hundreds of images of an object to train a good detection classifier. The best would be at least 1000 pictures for one object. To train a robust classifier, the training images should have random objects in the image and the desired objects and should have a variety of backgrounds and lighting conditions. There should be some images where the desired object is partially obscured, overlapped with something else, or only halfway in the picture.
I will use four different objects I want to detect (terrorist, terrorist head, counter-terrorist, and counter-terrorist head). I used to play CSGO with harmless bots to gather hundreds of these images playing on few different game maps. Also, I was grabbing some pictures from google to make them different from my game.
Label Pictures:
Here comes the best part. With all the pictures gathered, it’s time to label the desired objects in every picture. LabelImg is a great tool for labeling images, and its GitHub page has self-explanatory instructions on installing and using it.
Download and install LabelImg; when running this, you should get a GUI window. From here, choose to open dir and pick the directory that you saved all of your images to. Now, you can begin to annotate images with the create rectbox button. Draw your box, add the name in, and hit ok. Save, hit the next image, and repeat! Next, you can press the w key to draw the box and do ctrl+s to save faster. It took on average 1 hour for 100 images, which depends on the object quantity you have in an image. Keep in mind that this may take a while!
LabelImg saves a .xml file containing the label data for each image. These .xml files will be used to generate TFRecords, which are one of the inputs to the TensorFlow trainer. Once you have labeled and saved each image, there will be one .xml file for each image in the \test and \train directories.
Once you have labeled your images, we're going to separate them into training and testing groups. To do this, copy about 20% of your images and their annotation XML files to a new dir called - test and then copy the remaining ones to a new dir called - train.
With the images labeled, it’s time to generate the TFRecords that serve as input data to the TensorFlow training model. This tutorial uses the xml_to_csv.py and generate_tfrecord.py scripts from EdjeElectronics repository, with some slight modifications to work with our directory structure.
First, the image .xml data will be used to create .csv files containing all the data for the train and test images. From the main folder, if you are using the same file structure, issue the following command in the command prompt: python xml_to_csv.py.
This creates a train_labels.csv and test_labels.csv file in the CSGO_images folder. If you are using a different file structure, please change xml_to_csv.py accordingly. To avoid using cmd, I created a short .bat script called xml_to_csv.bat.
Next, open the generate_tfrecord.py file in a text editor, this file I also took from EdjeElectronics repository. Replace the label map with your own label map, where each object is assigned with an ID number. This same number assignment will be used when configuring the labelmap.pbtxt file.
For example, if you are training your own classifier, you will replace the following code in generate_tfrecord.py:
# TO-DO replace this with label map
def class_text_to_int(row_label):
if row_label == 'c':
return 1
elif row_label == 'ch':
return 2
elif row_label == 't':
return 3
elif row_label == 'th':
return 4
else:
return NoneThen, generate the TFRecord files by starting my created generate_tfrecord.bat file, which is issuing these commands from the local folder:
python generate_tfrecord.py --csv_input=CSGO_images\train_labels.csv --image_dir=CSGO_images\train --output_path= CSGO_images\train.record
python generate_tfrecord.py --csv_input=CSGO_images\test_labels.csv --image_dir=CSGO_images\test --output_path= CSGO_images\test.record
These lines generate a train.record and a test.record files in the training folder. These will be used to train the new object detection classifier.
The last thing to do before training is to create a label map and edit the training configuration file. The label map tells the trainer what each object is by defining a mapping of class names to class ID numbers. Use a text editor to create a new file and save it as labelmap.pbtxt in the training folder. (Make sure the file type is .pbtxt). In the text editor, copy or type the label map in the same format as below (the example below is the label map for my CSGO detector). The label map ID numbers should be the same as defined in the generate_tfrecord.py file.
item {
id: 1
name: 'c'
}
item {
id: 2
name: 'ch'
}
item {
id: 3
name: 't'
}
item {
id: 4
name: 'th'
}
Configure training:
Finally, the object detection training pipeline must be configured. It defines which model and what parameters will be used for training. This is the last step before running actual training. This tutorial code you can find on my GitHub page.
Navigate to your TensorFlow research\object_detection\samples\configs directory and copy the faster_rcnn_inception_v2_coco.config file into the CSGO_training directory. Then, open the file with a text editor; I personally use notepad++. There are several changes to make to this .config file, mainly changing the number of classes, examples and adding the file paths to the training data.
By the way, the paths must be entered with single forward slashes "/" or TensorFlow will give a file path error when trying to train the model. The paths must be in double quotation marks ( " ), not single quotation marks ( ' ).
Line 10. Change num_classes to the number of different objects you want the classifier to detect. For my CSGO object detection it would be:
num_classes : 4Line 107. Change fine_tune_checkpoint to:
fine_tune_checkpoint : "faster_rcnn_inception_v2_coco_2018_01_28/model.ckpt"Lines 122 and 124. In the train_input_reader section, change input_path and label_map_path to:
input_path: "CSGO_images/train.record"
label_map_path: "CSGO_training/labelmap.pbtxt"Line 128. Change num_examples to the number of images you have in the CSGO_images\test directory. I have 113 images, so I change them to:
num_examples: 113Lines 136 and 138. In the eval_input_reader section, change input_path and label_map_path to:
input_path: "CSGO_images/test.record"
label_map_path: "CSGO_training/labelmap.pbtxt"
Save the file after the changes have been made. That’s it! The training files are prepared and configured for training. One more step left before training.
Run the Training:
I have not been able to get model_main.py to work correctly yet, I run into errors. However, the train.py file is still available in the /object_detection/legacy folder. Simply move train.py from /object_detection/legacy into the /object_detection folder. Move our created CSGO_images and CSGO_training folders into the /object_detection folder and then continue with the following line in cmd from the object_detection directory:
python train.py --logtostderr --train_dir=CSGO_training_dir/ --pipeline_config_path=CSGO_training/faster_rcnn_inception_v2_coco.config
If everything has been set up correctly, TensorFlow will initialize the training. The initialization can take up to 30 to 60 seconds before the actual training begins. When training begins, it will look like this:
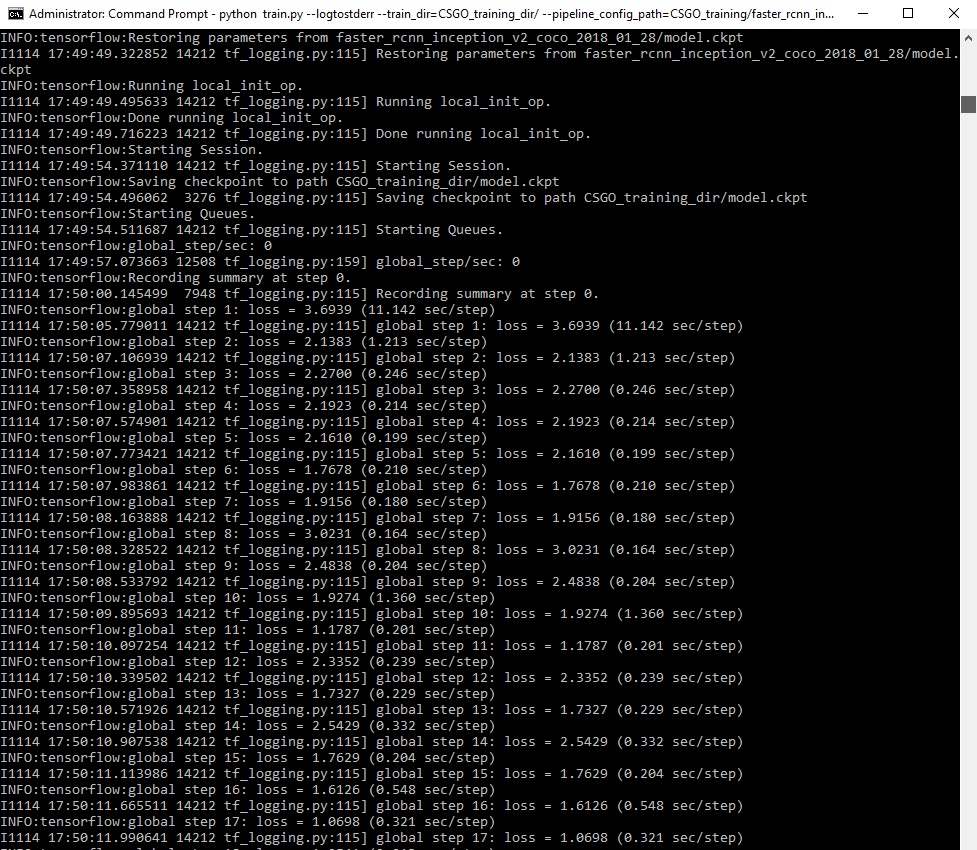
In the picture above, each step of training reports the loss. It will start high and get lower and lower as training progresses. For my training, it started at about 2-3 and quickly dropped below 0.5. I recommend allowing your model to train until the loss consistently drops below 0.05, which may take about 30,000 steps or about a few hours (depends on how powerful your CPU or GPU is). The loss numbers may be different while a different model is used. Also, it depends on the objects you want to detect.
You can, and you should view the progress of the training by using TensorBoard. To do this, open a new window of CMD and change to the C:\TensorFlow\research\object_detection directory (or directory you have) and issue the following command:
C:\TensorFlow\research\object_detection>tensorboard --logdir=CSGO_training_dir
This will create a local webpage on your local machine at YourPCName:6006, which can be viewed through a web browser. The TensorBoard page provides information and graphs that show how the training is progressing. One of the most important graph is the Loss graph, which shows the overall loss of the classifier over time:
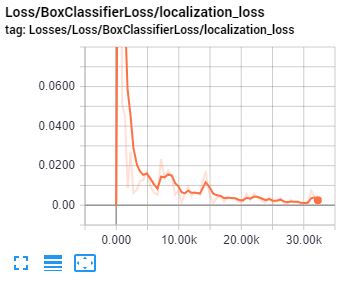
That’s all for this tutorial. In the next tutorial, a checkpoint at the highest number of steps will be used to generate the frozen inference graph and test it out.