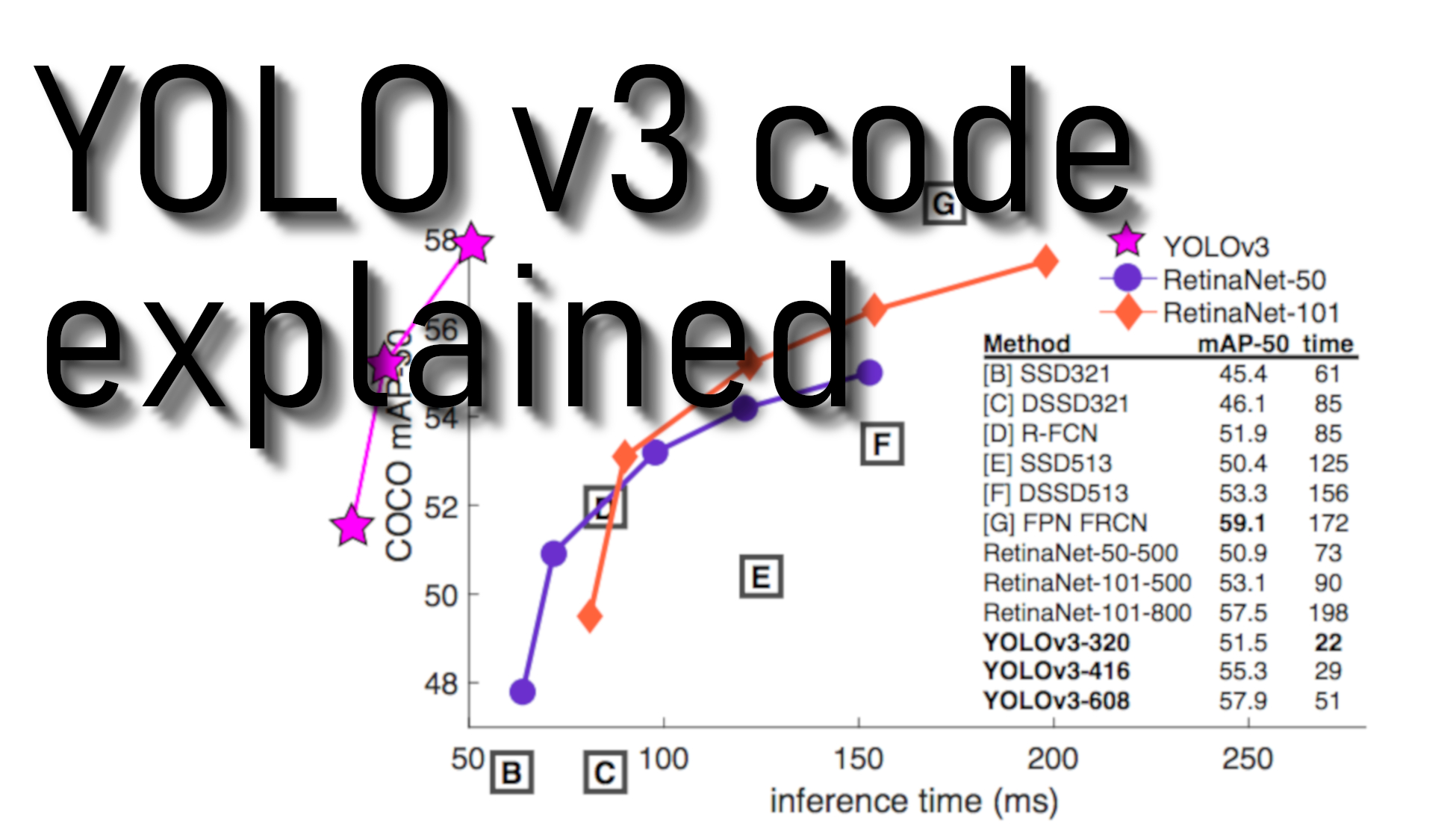
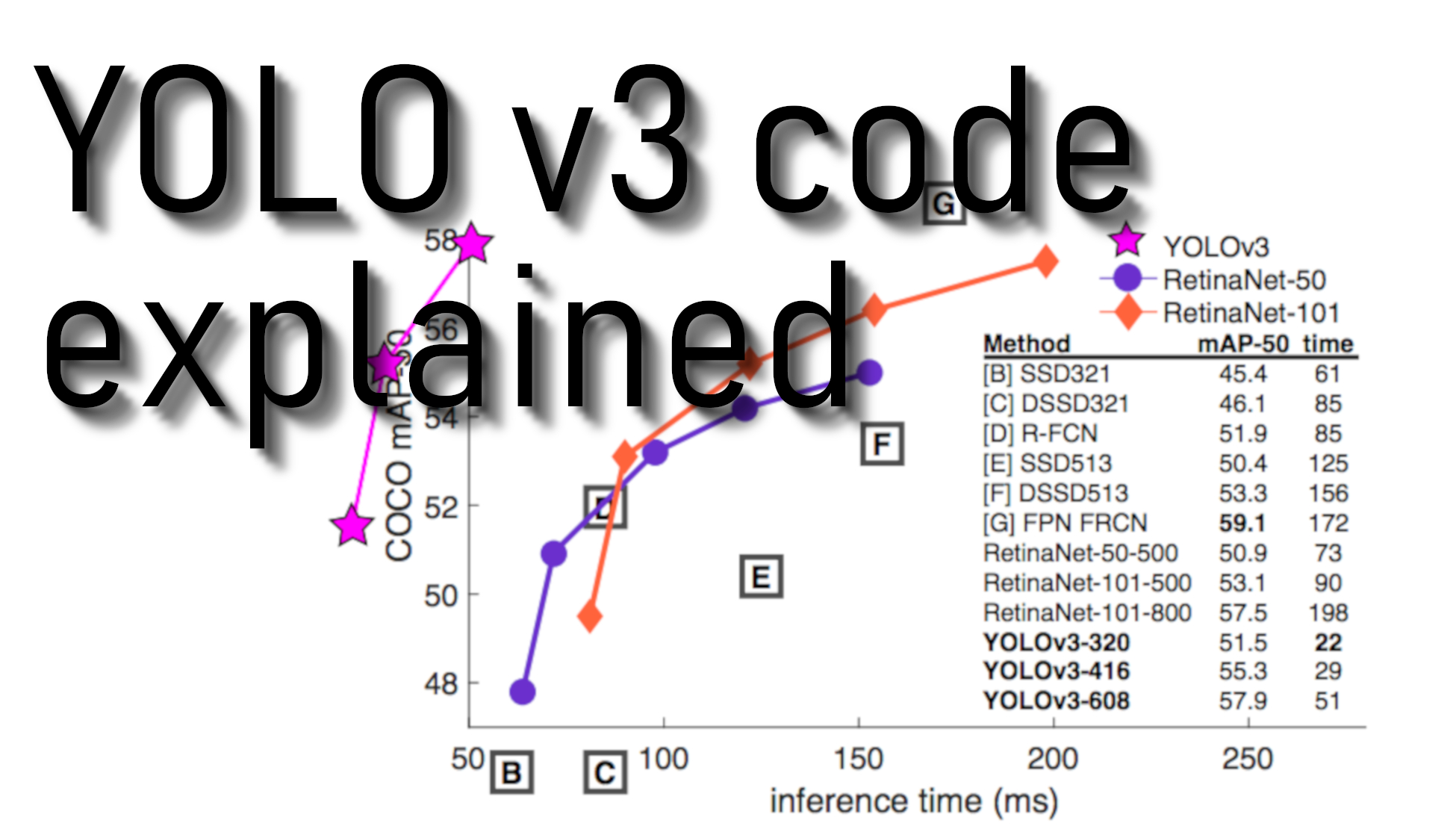
 If you hear about "You Only Look Once" the first time, you should know that it is an algorithm that uses convolutional neural networks for object detection. You only look once, or YOLO is one of the fastest object detection algorithms out there. Though it is not the most accurate object detection algorithm, it is an excellent choice when we need real-time detection without losing too much accuracy.
If you hear about "You Only Look Once" the first time, you should know that it is an algorithm that uses convolutional neural networks for object detection. You only look once, or YOLO is one of the fastest object detection algorithms out there. Though it is not the most accurate object detection algorithm, it is an excellent choice when we need real-time detection without losing too much accuracy.
To learn more about YOLO v3 and how it works, please read my YOLO v3 introduction tutorial to understand how it works before moving to code.
So what's great about object detection? Simply talking, YOLO is an algorithm that uses convolutional neural networks for object detection. In comparison to recognition algorithms, a detection algorithm predicts class labels and detects objects' locations.
In this tutorial, I will try to explain how TensorFlow YOLO v3 object detection works. If you only want to try or use it without getting deeper details, go to my GitHub repository: GitHub.
Tutorial content:
- Dependencies;
- Model hyperparameters;
- Model definition;
- Utility functions;
- Converting weights to Tensorflow format;
- Running model for images;
- Running model for video processing;
- To-Do list.
1. Dependencies
To build YOLO, we are going to need Tensorflow (deep learning), NumPy (numerical computation), cv2 (image processing) libraries, and seaborn (for text labels) libraries.
import tensorflow as tf
import numpy as np
import cv2
from seaborn import color_palette
2. Model hyperparameters
Next, we define some configurations for Yolo.
_BATCH_NORM_DECAY = 0.9
_BATCH_NORM_EPSILON = 1e-05
_LEAKY_RELU = 0.1
_ANCHORS = [(10, 13), (16, 30), (33, 23),
(30, 61), (62, 45), (59, 119),
(116, 90), (156, 198), (373, 326)]
_MODEL_SIZE = (416, 416) # refers to the input size of the model.3. Model definition
I referred to the official ResNet implementation in Tensorflow in terms of how to arrange the code. Almost every convolutional layer in Yolo has batch normalization after it. It helps the model train faster and reduces the variance between units (and total variance).
It's useful to define the batch_norm function since the model uses batch norms with shared parameters heavily. Also, YOLO uses convolution with fixed padding, which means that padding is defined only by the size of the kernel.
# Performs a batch normalization using a standard set of parameters
def batch_norm(inputs, training, data_format):
return tf.layers.batch_normalization(
inputs=inputs, axis=1 if data_format == 'channels_first' else 3,
momentum=_BATCH_NORM_DECAY, epsilon=_BATCH_NORM_EPSILON,
scale=True, training=training)3.1. ResNet implementation of fixed padding:
Arguments:
inputs: Tensor input to be padded;
kernel_size: The kernel to be used in the conv2d or max_pool2d;
data_format: The input format.
Returns:
A tensor with the same format as the input.
# ResNet implementation of fixed padding
def fixed_padding(inputs, kernel_size, data_format):
pad_total = kernel_size - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
if data_format == 'channels_first':
padded_inputs = tf.pad(inputs, [[0, 0], [0, 0],
[pad_beg, pad_end],
[pad_beg, pad_end]])
else:
padded_inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end],
[pad_beg, pad_end], [0, 0]])
return padded_inputs
# Strided 2-D convolution with explicit padding
def conv2d_fixed_padding(inputs, filters, kernel_size, data_format, strides=1):
if strides > 1:
inputs = fixed_padding(inputs, kernel_size, data_format)
return tf.layers.conv2d(
inputs=inputs, filters=filters, kernel_size=kernel_size,
strides=strides, padding=('SAME' if strides == 1 else 'VALID'),
use_bias=False, data_format=data_format)3.2. Feature extraction: Darknet-53
For feature extraction, YOLO uses a Darknet-53 neural net pre-trained on ImageNet. Same as ResNet, Darknet-53 has shortcut (residual block) connections, which help information from earlier layers flow further. We omit the last 3 layers (Avgpool, Connected, and Softmax) since we only need the features.
# Creates a residual block for Darknet
def darknet53_residual_block(inputs, filters, training, data_format, strides=1):
shortcut = inputs
inputs = conv2d_fixed_padding(inputs, filters=filters, kernel_size=1, strides=strides, data_format=data_format)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
inputs = conv2d_fixed_padding( inputs, filters=2 * filters, kernel_size=3, strides=strides, data_format=data_format)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
inputs += shortcut
return inputs
# Creates Darknet53 model for feature extraction
def darknet53(inputs, training, data_format):
inputs = conv2d_fixed_padding(inputs, filters=32, kernel_size=3, data_format=data_format)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
inputs = conv2d_fixed_padding(inputs, filters=64, kernel_size=3, strides=2, data_format=data_format)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
inputs = darknet53_residual_block(inputs, filters=32, training=training, data_format=data_format)
inputs = conv2d_fixed_padding(inputs, filters=128, kernel_size=3, strides=2, data_format=data_format)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
for _ in range(2):
inputs = darknet53_residual_block(inputs, filters=64, training=training, data_format=data_format)
inputs = conv2d_fixed_padding(inputs, filters=256, kernel_size=3, strides=2, data_format=data_format)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
for _ in range(8):
inputs = darknet53_residual_block(inputs, filters=128, training=training, data_format=data_format)
route1 = inputs
inputs = conv2d_fixed_padding(inputs, filters=512, kernel_size=3, strides=2, data_format=data_format)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
for _ in range(8):
inputs = darknet53_residual_block(inputs, filters=256, training=training, data_format=data_format)
route2 = inputs
inputs = conv2d_fixed_padding(inputs, filters=1024, kernel_size=3, strides=2, data_format=data_format)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
for _ in range(4):
inputs = darknet53_residual_block(inputs, filters=512, training=training, data_format=data_format)
return route1, route2, inputs3.3. Convolution layers
YOLO has a large number of convolutional layers. It's useful to group them into blocks:
# Creates convolution operations layer used after Darknet
def yolo_convolution_block(inputs, filters, training, data_format):
inputs = conv2d_fixed_padding(inputs, filters=filters, kernel_size=1, data_format=data_format)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
inputs = conv2d_fixed_padding(inputs, filters=2 * filters, kernel_size=3, data_format=data_format)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
inputs = conv2d_fixed_padding(inputs, filters=filters, kernel_size=1, data_format=data_format)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
inputs = conv2d_fixed_padding(inputs, filters=2 * filters, kernel_size=3, data_format=data_format)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
inputs = conv2d_fixed_padding(inputs, filters=filters, kernel_size=1, data_format=data_format)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
route = inputs
inputs = conv2d_fixed_padding(inputs, filters=2 * filters, kernel_size=3, data_format=data_format)
inputs = batch_norm(inputs, training=training, data_format=data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
return route, inputs3.4. Detection layers:
YOLO has 3 detection layers that detect on 3 different scales using respective anchors. For each cell in the feature map, the detection layer predicts n_anchors * (5 + n_classes) values using 1x1 convolution. For each scale, we have n_anchors = 3. 5 + n_classes that means that, respectively, to each of the 3 anchors, we will predict the 4 coordinates of the box, its confidence score (the probability of containing an object), and class probabilities.
Arguments:
inputs: Tensor input;
n_classes: Number of labels;
anchors: A list of anchor sizes;
img_size: The input size of the model;
data_format: The input format.
Returns:
Tensor output.
# Creates Yolo final detection layer
def yolo_layer(inputs, n_classes, anchors, img_size, data_format):
n_anchors = len(anchors)
inputs = tf.layers.conv2d(inputs, filters=n_anchors * (5 + n_classes),
kernel_size=1, strides=1, use_bias=True,
data_format=data_format)
shape = inputs.get_shape().as_list()
grid_shape = shape[2:4] if data_format == 'channels_first' else shape[1:3]
if data_format == 'channels_first':
inputs = tf.transpose(inputs, [0, 2, 3, 1])
inputs = tf.reshape(inputs, [-1, n_anchors * grid_shape[0] * grid_shape[1], 5 + n_classes])
strides = (img_size[0] // grid_shape[0], img_size[1] // grid_shape[1])
box_centers, box_shapes, confidence, classes = \
tf.split(inputs, [2, 2, 1, n_classes], axis=-1)
x = tf.range(grid_shape[0], dtype=tf.float32)
y = tf.range(grid_shape[1], dtype=tf.float32)
x_offset, y_offset = tf.meshgrid(x, y)
x_offset = tf.reshape(x_offset, (-1, 1))
y_offset = tf.reshape(y_offset, (-1, 1))
x_y_offset = tf.concat([x_offset, y_offset], axis=-1)
x_y_offset = tf.tile(x_y_offset, [1, n_anchors])
x_y_offset = tf.reshape(x_y_offset, [1, -1, 2])
box_centers = tf.nn.sigmoid(box_centers)
box_centers = (box_centers + x_y_offset) * strides
anchors = tf.tile(anchors, [grid_shape[0] * grid_shape[1], 1])
box_shapes = tf.exp(box_shapes) * tf.to_float(anchors)
confidence = tf.nn.sigmoid(confidence)
classes = tf.nn.sigmoid(classes)
inputs = tf.concat([box_centers, box_shapes, confidence, classes], axis=-1)
return inputs3.5. Upsample layer
To concatenate with shortcut outputs from Darknet-53 before applying detection on a different scale, we will upsample the feature map using nearest-neighbor interpolation.
Arguments:
inputs: Tensor input;
n_classes: Number of classes;
max_output_size: Max number of boxes to be selected for each class;
iou_threshold: Threshold for the IOU;
confidence_threshold: Threshold for the confidence score.
Returns:
A list containing class-to-boxes dictionaries for each sample in the batch.
# Upsamples to `out_shape` using nearest neighbor interpolation
def upsample(inputs, out_shape, data_format):
if data_format == 'channels_first':
inputs = tf.transpose(inputs, [0, 2, 3, 1])
new_height = out_shape[3]
new_width = out_shape[2]
else:
new_height = out_shape[2]
new_width = out_shape[1]
inputs = tf.image.resize_nearest_neighbor(inputs, (new_height, new_width))
if data_format == 'channels_first':
inputs = tf.transpose(inputs, [0, 3, 1, 2])
return inputs3.6. Non-max suppression
The model will produce many boxes, so we need a way to discard the boxes with low confidence scores. Also, to avoid having multiple boxes for one object, we will discard the boxes with high overlap, using non-max suppression for each class.
# Performs non-max suppression separately for each class
def non_max_suppression(inputs, n_classes, max_output_size, iou_threshold, confidence_threshold):
batch = tf.unstack(inputs)
boxes_dicts = []
for boxes in batch:
boxes = tf.boolean_mask(boxes, boxes[:, 4] > confidence_threshold)
classes = tf.argmax(boxes[:, 5:], axis=-1)
classes = tf.expand_dims(tf.to_float(classes), axis=-1)
boxes = tf.concat([boxes[:, :5], classes], axis=-1)
boxes_dict = dict()
for cls in range(n_classes):
mask = tf.equal(boxes[:, 5], cls)
mask_shape = mask.get_shape()
if mask_shape.ndims != 0:
class_boxes = tf.boolean_mask(boxes, mask)
boxes_coords, boxes_conf_scores, _ = tf.split(class_boxes,
[4, 1, -1],
axis=-1)
boxes_conf_scores = tf.reshape(boxes_conf_scores, [-1])
indices = tf.image.non_max_suppression(boxes_coords,
boxes_conf_scores,
max_output_size,
iou_threshold)
class_boxes = tf.gather(class_boxes, indices)
boxes_dict[cls] = class_boxes[:, :5]
boxes_dicts.append(boxes_dict)
return boxes_dicts
# Computes top left and bottom right points of the boxes
def build_boxes(inputs):
center_x, center_y, width, height, confidence, classes = \
tf.split(inputs, [1, 1, 1, 1, 1, -1], axis=-1)
top_left_x = center_x - width / 2
top_left_y = center_y - height / 2
bottom_right_x = center_x + width / 2
bottom_right_y = center_y + height / 2
boxes = tf.concat([top_left_x, top_left_y,
bottom_right_x, bottom_right_y,
confidence, classes], axis=-1)
return boxes3.7. Final model class
Finally, let's define the model class using all of the layers described previously.
Arguments:
n_classes: Number of class labels;
model_size: The input size of the model;
max_output_size: Max number of boxes to be selected for each class;
iou_threshold: Threshold for the IOU;
confidence_threshold: Threshold for the confidence score;
data_format: The input format.
# Yolo v3 model class
class Yolo_v3:
def __init__(self, n_classes, model_size, max_output_size, iou_threshold,
confidence_threshold, data_format=None):
if not data_format:
if tf.test.is_built_with_cuda():
data_format = 'channels_first'
else:
data_format = 'channels_last'
self.n_classes = n_classes
self.model_size = model_size
self.max_output_size = max_output_size
self.iou_threshold = iou_threshold
self.confidence_threshold = confidence_threshold
self.data_format = data_format
# Add operations to detect boxes for a batch of input images
def __call__(self, inputs, training):
with tf.variable_scope('yolo_v3_model'):
if self.data_format == 'channels_first':
inputs = tf.transpose(inputs, [0, 3, 1, 2])
inputs = inputs / 255
route1, route2, inputs = darknet53(inputs, training=training,
data_format=self.data_format)
route, inputs = yolo_convolution_block(
inputs, filters=512, training=training,
data_format=self.data_format)
detect1 = yolo_layer(inputs, n_classes=self.n_classes,
anchors=_ANCHORS[6:9],
img_size=self.model_size,
data_format=self.data_format)
inputs = conv2d_fixed_padding(route, filters=256, kernel_size=1,
data_format=self.data_format)
inputs = batch_norm(inputs, training=training,
data_format=self.data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
upsample_size = route2.get_shape().as_list()
inputs = upsample(inputs, out_shape=upsample_size,
data_format=self.data_format)
axis = 1 if self.data_format == 'channels_first' else 3
inputs = tf.concat([inputs, route2], axis=axis)
route, inputs = yolo_convolution_block(
inputs, filters=256, training=training,
data_format=self.data_format)
detect2 = yolo_layer(inputs, n_classes=self.n_classes,
anchors=_ANCHORS[3:6],
img_size=self.model_size,
data_format=self.data_format)
inputs = conv2d_fixed_padding(route, filters=128, kernel_size=1,
data_format=self.data_format)
inputs = batch_norm(inputs, training=training,
data_format=self.data_format)
inputs = tf.nn.leaky_relu(inputs, alpha=_LEAKY_RELU)
upsample_size = route1.get_shape().as_list()
inputs = upsample(inputs, out_shape=upsample_size,
data_format=self.data_format)
inputs = tf.concat([inputs, route1], axis=axis)
route, inputs = yolo_convolution_block(
inputs, filters=128, training=training,
data_format=self.data_format)
detect3 = yolo_layer(inputs, n_classes=self.n_classes,
anchors=_ANCHORS[0:3],
img_size=self.model_size,
data_format=self.data_format)
inputs = tf.concat([detect1, detect2, detect3], axis=1)
inputs = build_boxes(inputs)
boxes_dicts = non_max_suppression(
inputs, n_classes=self.n_classes,
max_output_size=self.max_output_size,
iou_threshold=self.iou_threshold,
confidence_threshold=self.confidence_threshold)
return boxes_dicts 4. Utility functions
Some utility functions will help us load images as NumPy arrays, load class names from the official file, and draw the predicted boxes.
Arguments:
img_names: A list of images names;
model_size: The input size of the model;
data_format: A format for the array returned ('channels_first' or 'channels_last').
Returns:
A 4D NumPy array.
# Loads images in a 4D array
def load_images(img_names, model_size):
imgs = []
img = cv2.imread(img_names)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, model_size)
img = np.array(img, dtype=np.float32)
img = np.expand_dims(img[:, :, :3], axis=0)
imgs.append(img)
imgs = np.concatenate(imgs)
return imgs
# Returns a list of class names read from `file_name`
def load_class_names(file_name):
with open(file_name, 'r') as f:
class_names = f.read().splitlines()
return class_names Draws detected boxes in images:
Arguments:
img_names: A list of images names;
boxes_dict: A class-to-boxes dictionary;
class_names: A class names list;
model_size: The input size of the model.
# Draws detected boxes
def draw_boxes(img_names, boxes_dicts, class_names, model_size):
colors = ((np.array(color_palette("hls", 80)) * 255)).astype(np.uint8)
for num, img_name, boxes_dict in zip(range(len(img_names)), img_names, boxes_dicts):
img = cv2.imread(img_names)
img = np.array(img, dtype=np.float32)
resize_factor = (img.shape[1] / model_size[0], img.shape[0] / model_size[1])
for cls in range(len(class_names)):
boxes = boxes_dict[cls]
color = colors[cls]
color = tuple([int(x) for x in color])
if np.size(boxes) != 0:
for box in boxes:
xy, confidence = box[:4], box[4]
confidence = ' '+str(confidence*100)[:2]
xy = [int(xy[i] * resize_factor[i % 2]) for i in range(4)]
cv2.rectangle(img, (xy[0], xy[1]), (xy[2], xy[3]), color[::-1], 2)
(test_width, text_height), baseline = cv2.getTextSize(class_names[cls]+confidence,
cv2.FONT_HERSHEY_SIMPLEX,
0.75, 1)
cv2.rectangle(img, (xy[0], xy[1]),
(xy[0] + test_width, xy[1] - text_height - baseline),
color[::-1], thickness=cv2.FILLED)
cv2.putText(img, class_names[cls]+confidence, (xy[0], xy[1] - baseline),
cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 0), 1)
if not os.path.exists('detections'):
os.mkdir('detections')
head, tail = os.path.split(img_names)
name = './detections/'+tail[:-4]+'_yolo.jpg'
cv2.imwrite(name, img)Draws detected boxes in video frame:
Arguments:
frame: A video frame;
frame_size: A tuple of (frame width, frame height);
boxes_dicts: A class-to-boxes dictionary;
class_names: A class names list;
model_size: The input size of the model.
# Draws detected boxes in a video frame
def draw_frame(frame, frame_size, boxes_dicts, class_names, model_size):
boxes_dict = boxes_dicts[0]
resize_factor = (frame_size[0] / model_size[1], frame_size[1] / model_size[0])
colors = ((np.array(color_palette("hls", 80)) * 255)).astype(np.uint8)
for cls in range(len(class_names)):
boxes = boxes_dict[cls]
color = colors[cls]
color = tuple([int(x) for x in color])
if np.size(boxes) != 0:
for box in boxes:
xy, confidence = box[:4], box[4]
confidence = ''
#confidence = ' '+str(confidence*100)[:2]
xy = [int(xy[i] * resize_factor[i % 2]) for i in range(4)]
cv2.rectangle(frame, (xy[0], xy[1]), (xy[2], xy[3]), color[::-1], 2)
(test_width, text_height), baseline = cv2.getTextSize(class_names[cls]+confidence,
cv2.FONT_HERSHEY_SIMPLEX,
0.75, 1)
cv2.rectangle(frame, (xy[0], xy[1]),
(xy[0] + test_width, xy[1] - text_height - baseline),
color[::-1], thickness=cv2.FILLED)
cv2.putText(frame, class_names[cls]+confidence, (xy[0], xy[1] - baseline),
cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 0), 1)5. Converting weights to Tensorflow format
Now it's time to load the official weights. We are going to iterate through the file and gradually create tf.assign operations.
Arguments:
variables: A list of tf.Variable to be assigned;
file_name: A name of a file containing weights.
Returns:
A list of assigned operations.
# Reshapes and loads official pretrained Yolo weights.
def load_weights(variables, file_name):
with open(file_name, "rb") as f:
# Skip first 5 values containing irrelevant info
np.fromfile(f, dtype=np.int32, count=5)
weights = np.fromfile(f, dtype=np.float32)
assign_ops = []
ptr = 0
# Load weights for Darknet part.
# Each convolution layer has batch normalization.
for i in range(52):
conv_var = variables[5 * i]
gamma, beta, mean, variance = variables[5 * i + 1:5 * i + 5]
batch_norm_vars = [beta, gamma, mean, variance]
for var in batch_norm_vars:
shape = var.shape.as_list()
num_params = np.prod(shape)
var_weights = weights[ptr:ptr + num_params].reshape(shape)
ptr += num_params
assign_ops.append(tf.assign(var, var_weights))
shape = conv_var.shape.as_list()
num_params = np.prod(shape)
var_weights = weights[ptr:ptr + num_params].reshape(
(shape[3], shape[2], shape[0], shape[1]))
var_weights = np.transpose(var_weights, (2, 3, 1, 0))
ptr += num_params
assign_ops.append(tf.assign(conv_var, var_weights))
# Loading weights for Yolo part.
# 7th, 15th and 23rd convolution layer has biases and no batch norm.
ranges = [range(0, 6), range(6, 13), range(13, 20)]
unnormalized = [6, 13, 20]
for j in range(3):
for i in ranges[j]:
current = 52 * 5 + 5 * i + j * 2
conv_var = variables[current]
gamma, beta, mean, variance = \
variables[current + 1:current + 5]
batch_norm_vars = [beta, gamma, mean, variance]
for var in batch_norm_vars:
shape = var.shape.as_list()
num_params = np.prod(shape)
var_weights = weights[ptr:ptr + num_params].reshape(shape)
ptr += num_params
assign_ops.append(tf.assign(var, var_weights))
shape = conv_var.shape.as_list()
num_params = np.prod(shape)
var_weights = weights[ptr:ptr + num_params].reshape(
(shape[3], shape[2], shape[0], shape[1]))
var_weights = np.transpose(var_weights, (2, 3, 1, 0))
ptr += num_params
assign_ops.append(tf.assign(conv_var, var_weights))
bias = variables[52 * 5 + unnormalized[j] * 5 + j * 2 + 1]
shape = bias.shape.as_list()
num_params = np.prod(shape)
var_weights = weights[ptr:ptr + num_params].reshape(shape)
ptr += num_params
assign_ops.append(tf.assign(bias, var_weights))
conv_var = variables[52 * 5 + unnormalized[j] * 5 + j * 2]
shape = conv_var.shape.as_list()
num_params = np.prod(shape)
var_weights = weights[ptr:ptr + num_params].reshape(
(shape[3], shape[2], shape[0], shape[1]))
var_weights = np.transpose(var_weights, (2, 3, 1, 0))
ptr += num_params
assign_ops.append(tf.assign(conv_var, var_weights))
return assign_ops6. Running model for images
Now we can run the model using some sample images.
# Yolo v3 image detection
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import tensorflow as tf
import sys
import cv2
from yolo_v3 import Yolo_v3
from utils import load_images, load_class_names, draw_boxes
_MODEL_SIZE = (416, 416)
_CLASS_NAMES_FILE = 'coco.names'
_MAX_OUTPUT_SIZE = 50
detection_result = {}
def main(iou_threshold, confidence_threshold, input_names):
global detection_result
class_names = load_class_names(_CLASS_NAMES_FILE)
n_classes = len(class_names)
model = Yolo_v3(n_classes=n_classes, model_size=_MODEL_SIZE,
max_output_size=_MAX_OUTPUT_SIZE,
iou_threshold=iou_threshold,
confidence_threshold=confidence_threshold)
batch = load_images(input_names, model_size=_MODEL_SIZE)
inputs = tf.placeholder(tf.float32, [1, *_MODEL_SIZE, 3])
detections = model(inputs, training=False)
saver = tf.train.Saver(tf.global_variables(scope='yolo_v3_model'))
with tf.Session() as sess:
saver.restore(sess, './weights/model.ckpt')
detection_result = sess.run(detections, feed_dict={inputs: batch})
draw_boxes(input_names, detection_result, class_names, _MODEL_SIZE)
print('Detections have been saved successfully.')
if __name__ == '__main__':
main(0.5, 0.5, "images/office.jpg")7. Running model for video processing
I also applied the same algorithm to video detections. I found a short video on youtube where the car is driving through the city.
# Yolo v3 video detection
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import tensorflow as tf
import sys
import cv2
from yolo_v3 import Yolo_v3
from utils import load_images, load_class_names, draw_boxes, draw_frame
_MODEL_SIZE = (416, 416)
_CLASS_NAMES_FILE = 'coco.names'
_MAX_OUTPUT_SIZE = 50
detection_result = {}
def main(iou_threshold, confidence_threshold, input_names):
global detection_result
class_names = load_class_names(_CLASS_NAMES_FILE)
n_classes = len(class_names)
model = Yolo_v3(n_classes=n_classes, model_size=_MODEL_SIZE,
max_output_size=_MAX_OUTPUT_SIZE,
iou_threshold=iou_threshold,
confidence_threshold=confidence_threshold)
inputs = tf.placeholder(tf.float32, [1, *_MODEL_SIZE, 3])
detections = model(inputs, training=False)
saver = tf.train.Saver(tf.global_variables(scope='yolo_v3_model'))
with tf.Session() as sess:
saver.restore(sess, './weights/model.ckpt')
win_name = 'Video detection'
cv2.namedWindow(win_name)
cap = cv2.VideoCapture(input_names)
frame_size = (cap.get(cv2.CAP_PROP_FRAME_WIDTH), cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fourcc = int(cap.get(cv2.CAP_PROP_FOURCC))
fps = cap.get(cv2.CAP_PROP_FPS)
if not os.path.exists('detections'):
os.mkdir('detections')
head, tail = os.path.split(input_names)
name = './detections/'+tail[:-4]+'_yolo.mp4'
out = cv2.VideoWriter(name, fourcc, fps, (int(frame_size[0]), int(frame_size[1])))
try:
print("Show video")
while(cap.isOpened()):
ret, frame = cap.read()
if not ret:
break
resized_frame = cv2.resize(frame, dsize=_MODEL_SIZE[::-1], interpolation=cv2.INTER_NEAREST)
detection_result = sess.run(detections, feed_dict={inputs: [resized_frame]})
draw_frame(frame, frame_size, detection_result, class_names, _MODEL_SIZE)
if ret == True:
cv2.imshow(win_name, frame)
out.write(frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
finally:
cv2.destroyAllWindows()
cap.release()
print('Detections have been saved successfully.')
if __name__ == '__main__':
main(0.5, 0.5, "input/driving.mp4")Future tutorials To-Do list:
- Write YOLOv3 in Keras
- Train custom YOLOv3 detection model
- Test YOLOv3 FPS performance on CS:GO game