Welcome everyone back to my other tutorial, where we'll test our trained Transformer model, which I trained for the Spanish-to-English Translation task. I recommend reading my previous tutorials for details, what transformers are, what dataset I used, and how I trained my custom Transformer model. It's crucial to understand the Encoder and Decoder layers, including the Attention mechanism, to know how to use them while training.
But this part is not about training, but how to run inference (predictions) with our trained models. While I don't understand Spanish, I created a specific tutorial for translating Spanish to English. This was just an example of how to train a Transformer model from scratch, save it, and convert it to ONNX format for portability.
First of all, you can download my trained model file and Tensorboard logs from this link.
Now, let's delve into the details of training this model. This training process took much longer than expected because the dataset was quite substantial. It consisted of one million different sentences in both English and Spanish, explicitly using the OPUS100 dataset. It's a massive dataset, and I trained it completely.
Training this model was quite time-consuming. It took me a total of six days to train this Transformer model. Considering that this was just for fun, I had the luxury to tie up the GPU for this duration. As you can see in the TensorBoard graph, the loss was steadily decreasing throughout the training process. The orange curve represents the training loss, while the blue curve represents the validation loss. The model was consistently improving:
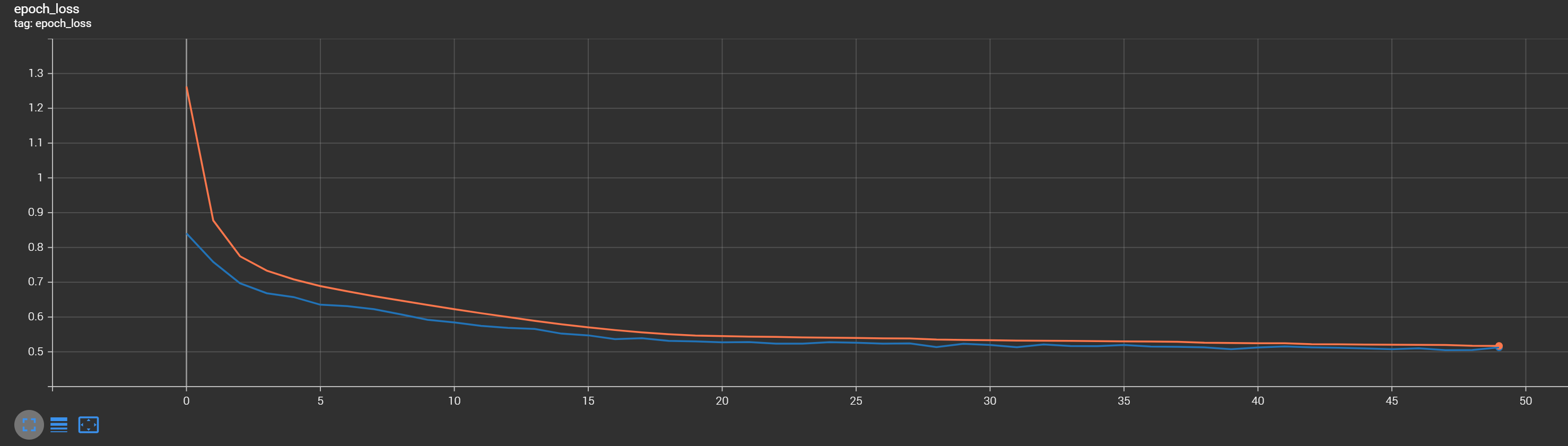
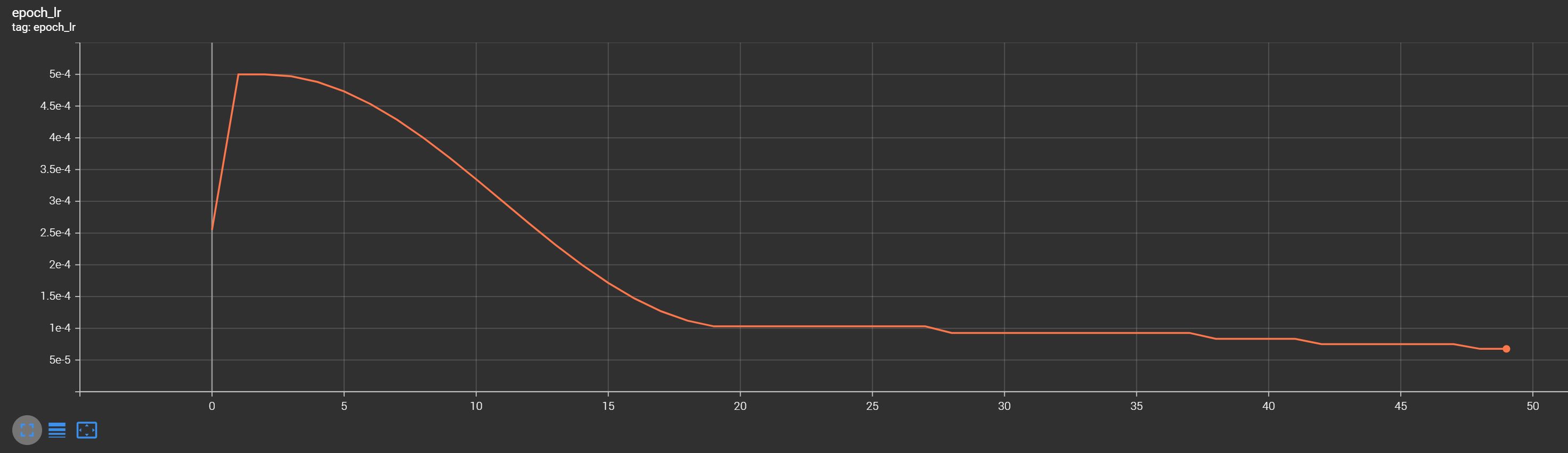
I also employed a special learning rate callback WarmupCosineDecay during training. It started with a certain warmup learning rate and gradually decreased following a cosine curve. Additionally, I implemented early stopping to prevent overfitting, but it seems it reached the maximum training epochs count that I sat in the training pipeline instead of early stopping:
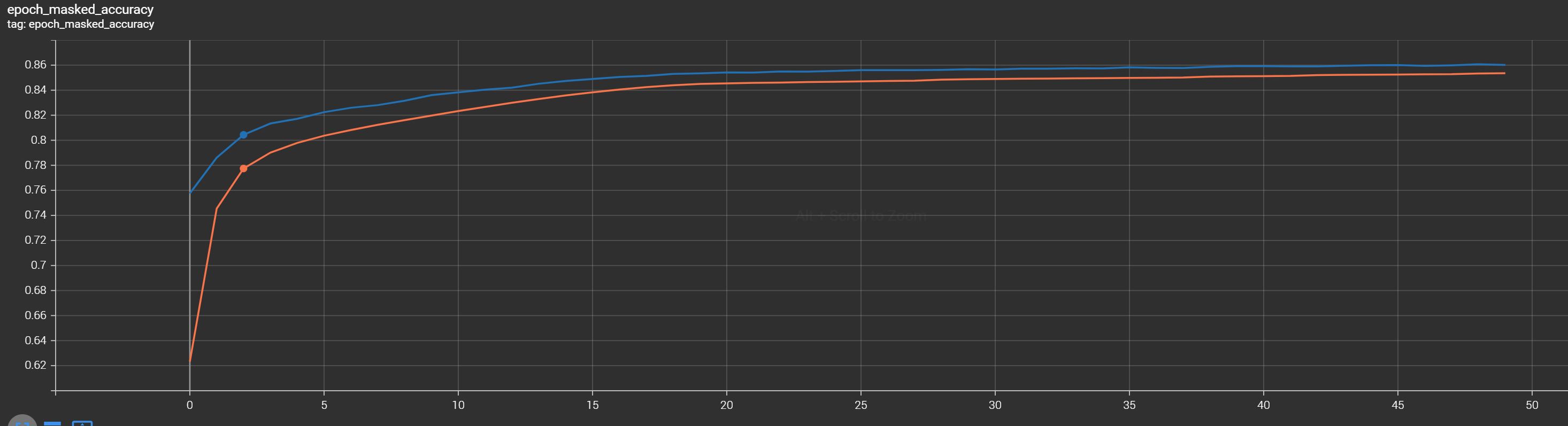
After 50 epochs of training, the model achieved an accuracy of 86%. While this might be a lower accuracy, it's a satisfactory result considering the relatively small model size (with only 7 million trainable parameters for both encoder and decoder). Training such a model from scratch with access to a robust GPU is recommended. There are open-source pre-trained models available for practical use.
Inference with the ONNX model:
Let's discuss how to run inference with the trained model. I've prepared a test script for running inference on any operating system using the ONNX model. This approach simplifies model deployment significantly. Instead of installing the TensorFlow library and defining all the model layers and dependencies, you only need to install the ONNX runtime and load the model.
To run this code, you need to install two libraries:
- onnxruntime (onnxruntime-gpu for GPU inference)
- mltu (pip install mltu==1.1.0)
This is the code for inference:
import numpy as np
import time
from mltu.tokenizers import CustomTokenizer
from mltu.inferenceModel import OnnxInferenceModel
class PtEnTranslator(OnnxInferenceModel):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.new_inputs = self.model.get_inputs()
self.tokenizer = CustomTokenizer.load(self.metadata["tokenizer"])
self.detokenizer = CustomTokenizer.load(self.metadata["detokenizer"])
def predict(self, sentence):
start = time.time()
tokenized_sentence = self.tokenizer.texts_to_sequences([sentence])[0]
encoder_input = np.pad(tokenized_sentence, (0, self.tokenizer.max_length - len(tokenized_sentence)), constant_values=0).astype(np.int64)
tokenized_results = [self.detokenizer.start_token_index]
for index in range(self.detokenizer.max_length - 1):
decoder_input = np.pad(tokenized_results, (0, self.detokenizer.max_length - len(tokenized_results)), constant_values=0).astype(np.int64)
input_dict = {
self.model._inputs_meta[0].name: np.expand_dims(encoder_input, axis=0),
self.model._inputs_meta[1].name: np.expand_dims(decoder_input, axis=0),
}
preds = self.model.run(None, input_dict)[0] # preds shape (1, 206, 29110)
pred_results = np.argmax(preds, axis=2)
tokenized_results.append(pred_results[0][index])
if tokenized_results[-1] == self.detokenizer.end_token_index:
break
results = self.detokenizer.detokenize([tokenized_results])
return results[0], time.time() - start
def read_files(path):
with open(path, "r", encoding="utf-8") as f:
en_train_dataset = f.read().split("\n")[:-1]
return en_train_dataset
# Path to dataset
en_validation_data_path = "Datasets/en-es/opus.en-es-dev.en"
es_validation_data_path = "Datasets/en-es/opus.en-es-dev.es"
en_validation_data = read_files(en_validation_data_path)
es_validation_data = read_files(es_validation_data_path)
# Consider only sentences with length <= 500
max_lenght = 500
val_examples = [[es_sentence, en_sentence] for es_sentence, en_sentence in zip(es_validation_data, en_validation_data) if len(es_sentence) <= max_lenght and len(en_sentence) <= max_lenght]
translator = PtEnTranslator("Models/09_translation_transformer/202308241514/model.onnx")
val_dataset = []
for es, en in val_examples:
results, duration = translator.predict(es)
print("Spanish: ", es.lower())
print("English: ", en.lower())
print("English pred:", results)
print(duration)
print()One important aspect to note is that I converted the model to ONNX format after training for ease of deployment. This conversion includes both the model architecture and the tokenizers, making it more straightforward to use in a production environment. I also saved tokenizers into JSON format, which we can load into the CustomTokenizer object. Still, the onnx supports a fantastic functionality: I could serialize these dictionaries and export them straight inside the model file.
In the test script above, I load the ONNX model and initialize tokenizers for Spanish and English. Tokenization is essential to prepare the input sentence for the model. The decoder input is created by starting with a special start token. Then, I tokenize and pad the input sentence and construct the input dictionary required for ONNX.
With the input dictionary ready, I pass it to the ONNX model, which returns prediction results. The prediction is a sequence of tokens, and I extract the first token, which is the most important one. This token represents the predicted translation.
For a deeper understanding of how it works, I recommend watching my YouTube video above, where I explain this script step-by-step.
I demonstrate inference with several examples, showing that the model produces reasonable translations for various sentences. While imperfect, it showcases that the Transformer model is functional for language translation tasks. Here are a few examples:
Spanish: no recuerdo por qué fue la pelea.
English: i don't even remember what the fight was about.
English pred: i don't remember why it was the fight.
0.47699928283691406
Spanish: estos son los sitios en que cada congreso ha tenido lugar:
English: here are the sites of each of those that have taken place:
English pred: these are the places in which each congress has taken place:
0.7539956569671631
Spanish: sí. soy el hombre que mató a barbanegra.
English: i'm the man who killed blackbeard.
English pred: i'm the man who killed barbanegra.
0.5812220573425293
Spanish: no te hagas el inteligente.
English: don't get smart.
English pred: don't make the smart one.
0.3790006637573242
Spanish: ¿existe un límite de cuándo se padece y cuándo no?
English: is there an exact moment in the life of a soldier before which he is not suffering from shell-shock and after which he is?
English pred: is there a limit of when he suffers and when not?
0.6098625659942627
Spanish: sí, joe.
English: yes, joe.
English pred: yeah, joe.
0.19399309158325195
Spanish: ¿por qué dos meses?
English: why two months?
English pred: why two months?
0.21761870384216309Here are seven different examples from the validation dataset, where I try to translate Spanish sentences to English. Also, I include the duration of how long inference took on my 1080TI GPU. We can clearly see that my Transformer model learned to translate Spanish to English. It's not perfect, but it works!
Conclusion:
To summarize, this tutorial series aimed to provide a comprehensive understanding of Transformers, from theory to practical application. We successfully trained a Transformer model for language translation, even though it required substantial computational resources. The key takeaway is that it's possible to train a custom Transformer from scratch, but using pre-trained models is more practical for real-world applications.
I may explore using this model in future tutorials for other tasks, such as speech-to-text synthesis. However, keep in mind that using pre-trained models and building upon them is often a more efficient approach.
Thank you for reading this tutorial!
You can download my trained model file and Tensorboard logs from this link.
Tutorial code on GitHub.