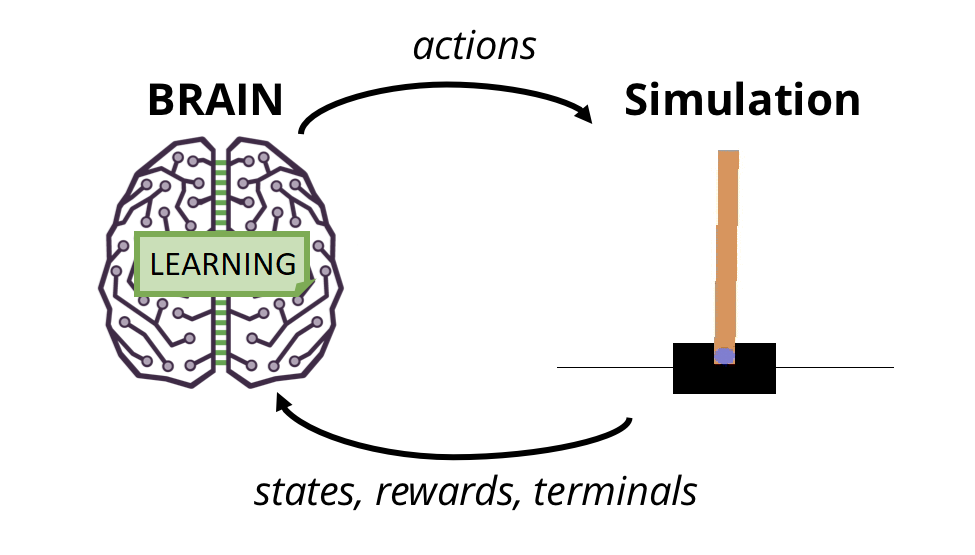
PyLessons September 22, 2019 Introduction to Reinforcement Learning This is an introduction tutorial to Reinforcement Learning. To understand everything from basics I will start with a simple game called - CartPole
PyLessons October 14, 2019 Solving the Cartpole with Double Deep Q Network This is the second reinforcement tutorial part, where we'll make our environment use two (Double) neural networks to train our main model
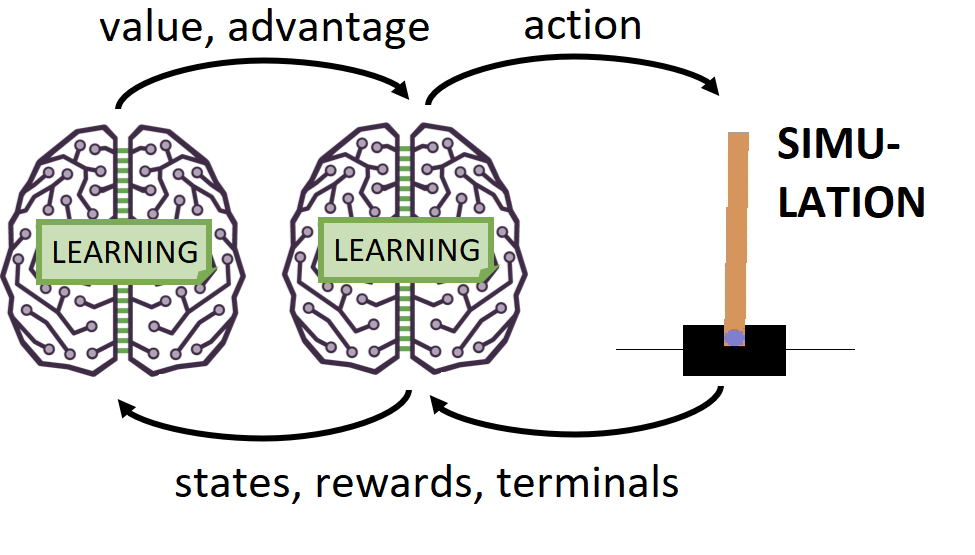
PyLessons October 16, 2019 Solving the Cartpole with Dueling Double Deep Q Network In this post, we’ll be covering Dueling DQN networks for reinforcement learning. This architecture is an improvement from our previous DDQN tutorial.
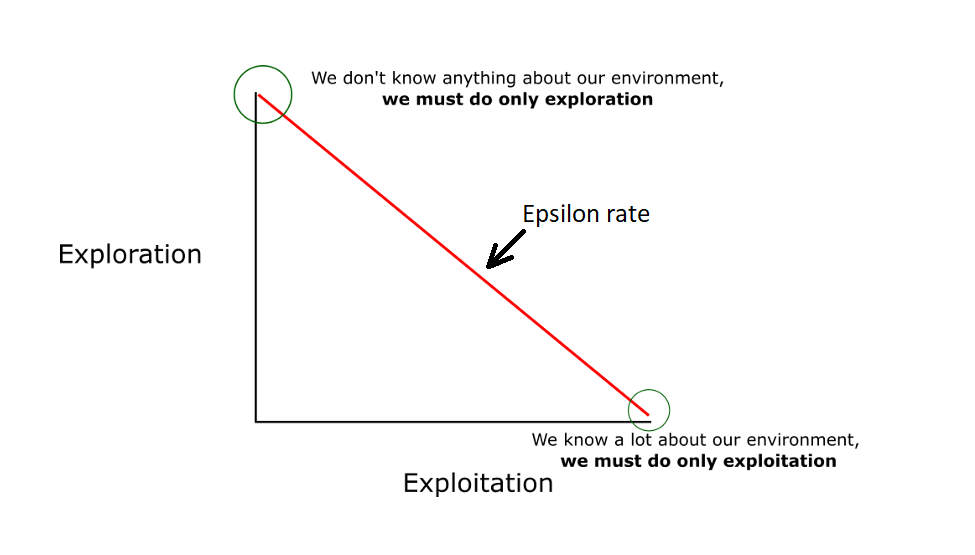
PyLessons November 03, 2019 Epsilon Greedy in Deep Q Learning In this part, we'll cover the Epsilon Greedy method used in Deep Q Learning and we'll fix/prepare our source code for PER method
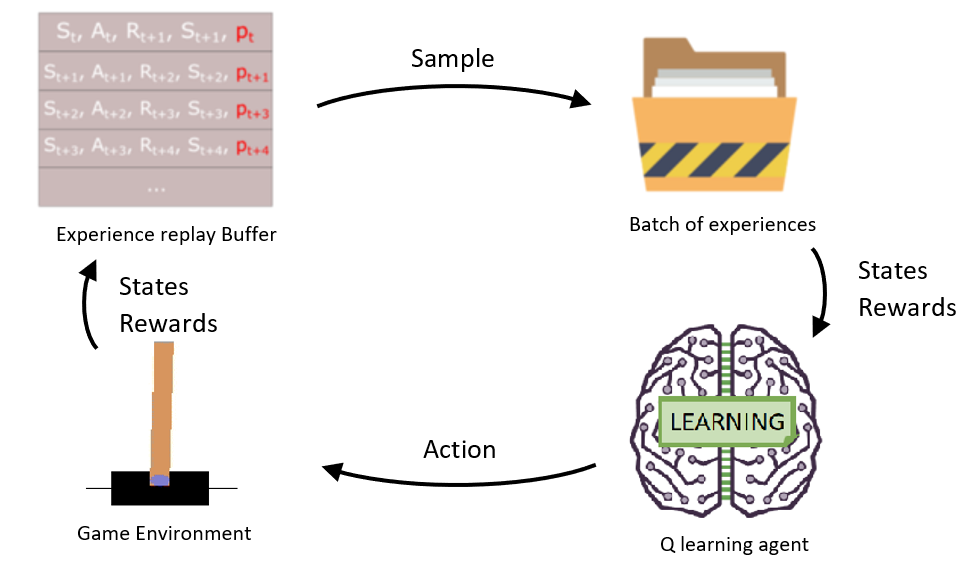
PyLessons November 14, 2019 D3QN Agent with Prioritized Experience Replay Now we will try to change the sampling distribution by using a criterion to define the priority of each tuple of experience.
PyLessons November 19, 2019 DQN PER with Convolutional Neural Networks Now I will show you how to implement DQN with CNN. After this tutorial, you'll be able to create an agent that successfully plays almost ‘any’ game using only pixel inputs
PyLessons February 24, 2020 A.I. learns to play Pong with Deep Q Network In this tutorial, I'll implement a Deep Neural Network for Reinforcement Learning (Deep Q Network), and we will see it learns and finally becomes good enough to beat the computer in Pong!
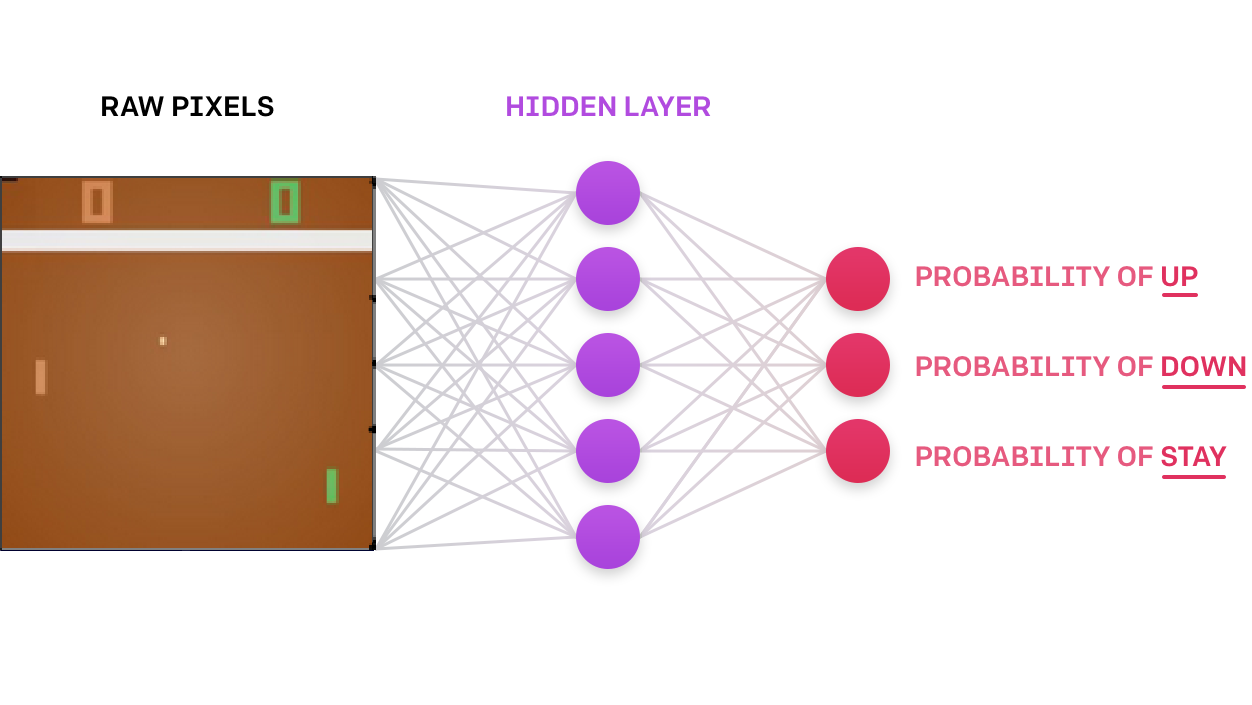
PyLessons March 18, 2020 Introduction to Reinforcement Learning Policy Gradient To wrap up deep reinforcement learning, I’ll introduce the types of agents beyond DQN’s (Value, Model, Policy optimization, and Imitation Learning). We'll implement Policy Gradient!
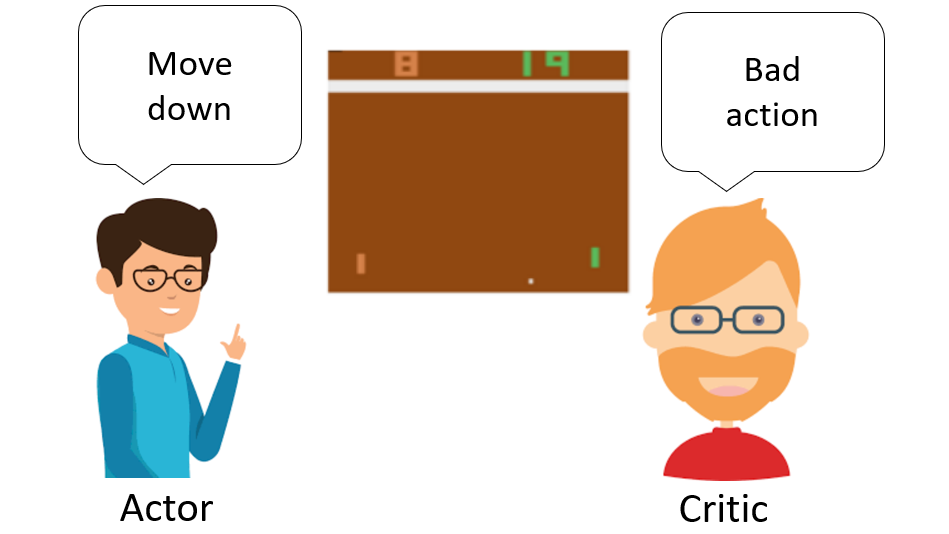
PyLessons March 20, 2020 Introduction to Advantage Actor-Critic method (A2C) Today, we'll study a Reinforcement Learning method that we can call a 'hybrid method': Actor-Critic. This algorithm combines the value optimization and policy optimization approaches
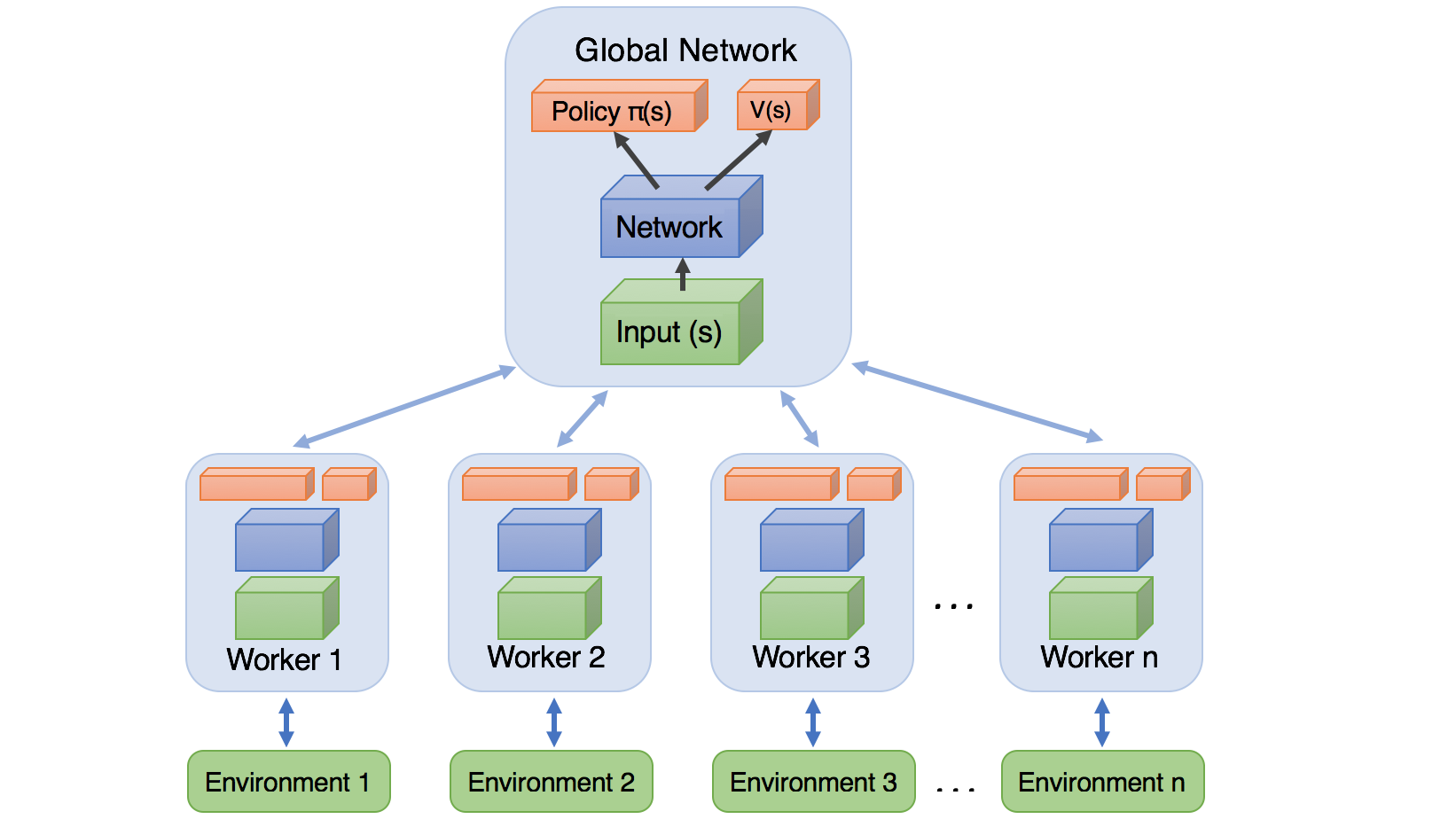
PyLessons March 22, 2020 Asynchronous Advantage Actor-Critic (A3C) algorithm In this tutorial, I will provide an implementation of the Asynchronous Advantage Actor-Critic (A3C) algorithm in Tensorflow and Keras. We will use it to solve a simple challenge in the Pong environmens
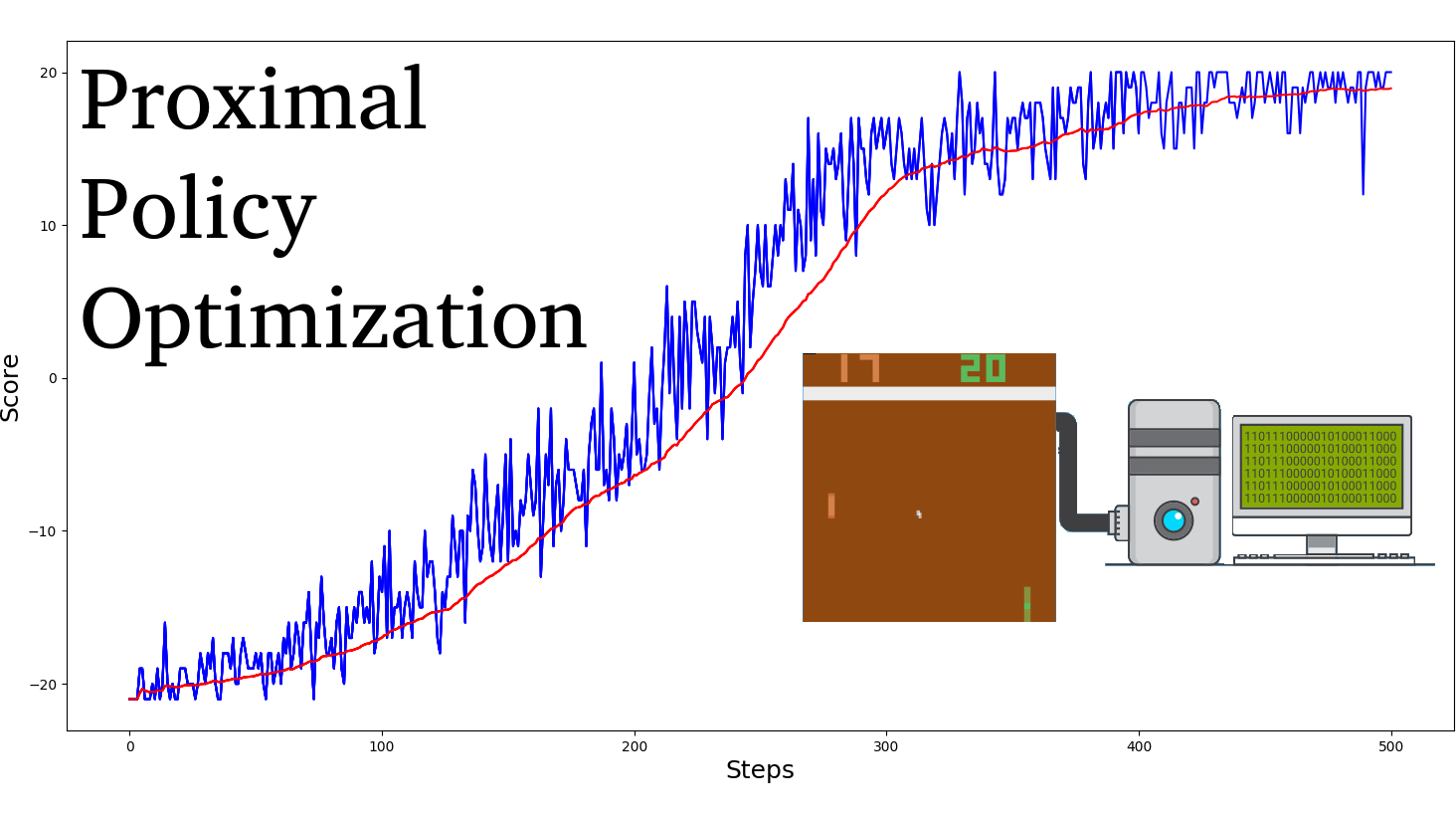
PyLessons March 25, 2020 Policy Optimization (PPO) In this tutorial, we'll dive into the understanding of the PPO architecture and we'll implement a Proximal Policy Optimization (PPO) agent that learns to play Pong-v0
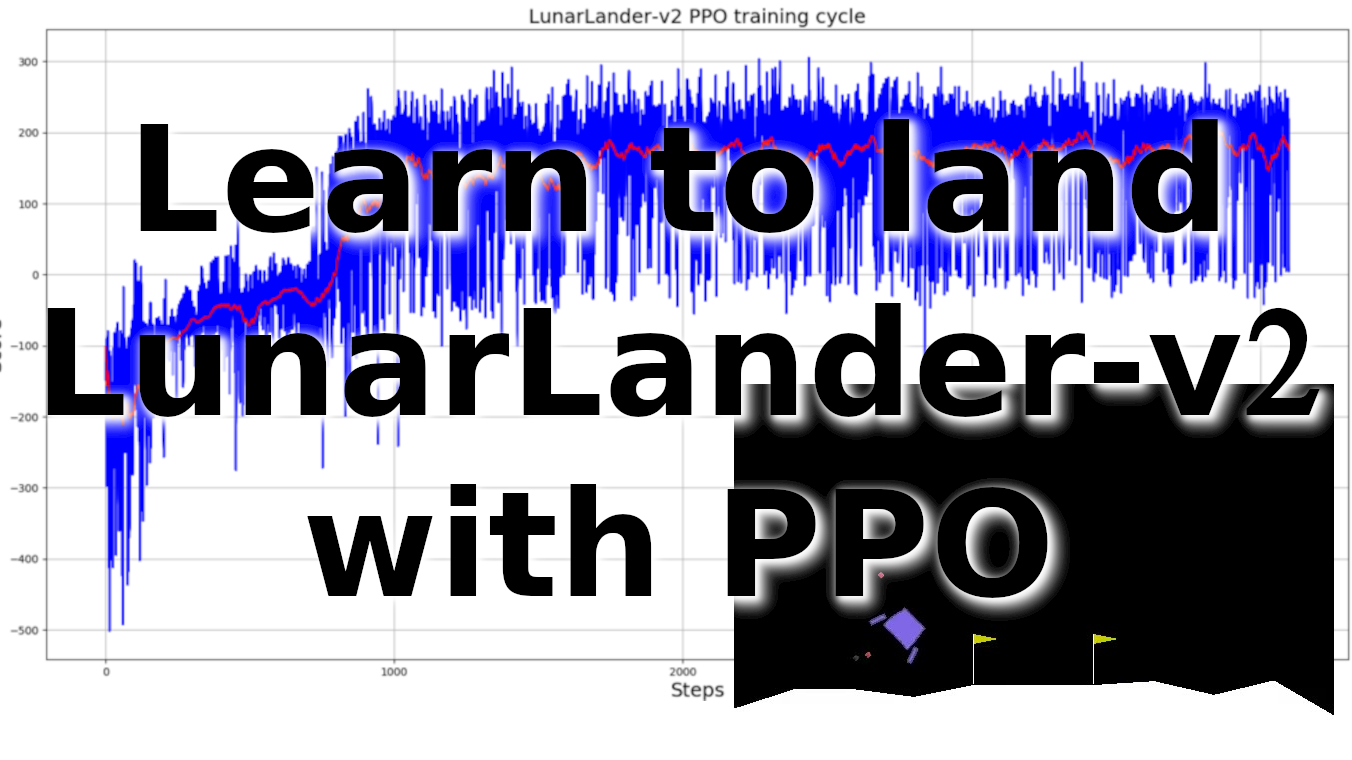
PyLessons November 13, 2020 LunarLander-v2 with Proximal Policy Optimization In this step-by-step reinforcement learning tutorial with gym and TensorFlow 2. I’ll show you how to implement a PPO for teaching an AI agent how to land a rocket (Lunarlander-v2)
PyLessons November 23, 2020 BipedalWalker-v3 with Continuous Proximal Policy Optimization In this tutorial, we'll solve the BipedalWalker-v3 environment, which is a very hard environment in the Gym. Our agent should run very fast, should not trip himself off, should use as little energy as possible...